|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Лютикова Л.А.
Применение логического моделирования для анализа и классификации медицинских данных с целью диагностики
// Программные системы и вычислительные методы.
2023. № 4.
С. 61-72.
DOI: 10.7256/2454-0714.2023.4.68876 EDN: KIUUOL URL: https://nbpublish.com/library_read_article.php?id=68876
Применение логического моделирования для анализа и классификации медицинских данных с целью диагностики
Лютикова Лариса Адольфовна
кандидат физико-математических наук
заведующий отделом, ИПМА КБНЦ РАН
360000, Россия, Республика Кабардино-Балкария, г. Нальчик, ул. Шортанова, 89а
Lyutikova Larisa Adol'fovna
PhD in Physics and Mathematics
Head of department, Institute of Applied Mathematics and Automation
360000, Russia, respublika Kabardino-Balkariya, g. Nal'chik, ul. Shortanova, 89a

|
lylarisa@yandex.ru
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0714.2023.4.68876
EDN: KIUUOL
Дата направления статьи в редакцию:
03-11-2023
Дата публикации:
25-11-2023
Аннотация:
Предметом исследования является логический подход к анализу данных и разработка программного инструментария, способного определять скрытые закономерности, даже с ограниченным количеством данных. Входные данные состоят из показателей диагностики пациентов, их диагнозов и опыта врачей, полученного в ходе медицинской практики. Метод исследования – разработка программного инструментария на основе систем многозначной логики предикатов для анализа данных пациентов. Данный подход рассматривает исходные данные как набор общих правил, среди которых можно выделить те правила, которые достаточны для объяснения всех наблюдаемых данных. Эти правила, в свою очередь, являются генеративными для рассматриваемой области и помогают лучше понять природу изучаемых объектов. Новизна исследования заключается в применении многозначной логики для анализа ограниченного объема медицинских данных пациентов с целью определения наиболее вероятного диагноза с заданной точностью. Предложенный подход позволяет обнаруживать скрытые закономерности в симптомах и результатах обследований пациентов, классифицировать их и выделять уникальные признаки различных форм гастрита. В отличие от нейронных сетей, логический анализ является прозрачным и не требует обучения на больших объемах данных. Выводы исследования показывают возможность такого подхода для диагностики при нехватке информации, а также предложение альтернатив при не достижении требуемой точности диагноза.
Ключевые слова:
диагностика, связи, многозначная логика, данные, анализ, скрытые закономерности, классификатор, правила продукции, обучение, сойства
Abstract: The subject of the research is a logical approach to data analysis and the development of software tools capable of identifying hidden patterns, even with a limited amount of data. The input data consists of indicators of the diagnosis of patients, their diagnoses and the experience of doctors obtained in the course of medical practice. The research method is the development of software tools based on systems of multivalued predicate logic for the analysis of patient data. This approach considers the source data as a set of general rules, among which it is possible to distinguish those rules that are sufficient to explain all the observed data. These rules, in turn, are generative for the area under consideration and help to better understand the nature of the objects under study. The novelty of the study lies in the use of multivalued logic to analyze a limited amount of medical data of patients in order to determine the most likely diagnosis with a given accuracy. The proposed approach makes it possible to detect hidden patterns in the symptoms and results of patient examinations, classify them and identify unique signs of various forms of gastritis. Unlike neural networks, logical analysis is transparent and does not require training on large amounts of data. The conclusions of the study show the possibility of such an approach for diagnosis with a lack of information, as well as the offer of alternatives if the required accuracy of diagnosis is not achieved.
Keywords: diagnostics, communications, multivalued logic, data, analysis, hidden patterns, classifier, product rules, training, properties
Введение
Медицинская диагностика активно использует методы машинного обучения, которые позволяют эффективно анализировать данные и поддерживать процесс постановки диагноза.
Одним из преимуществ является возможность обрабатывать большие объемы информации и находить скрытые закономерности, помогающие прогнозировать заболевания и принимать решения. В отличие от ручного кодирования, алгоритмы самостоятельно находят признаки и строят модели на основе обучающих данных.
Существующие методы можно разделить на такие как классификация пациентов по симптомам для диагностики конкретных заболеваний. Кластеризация для выделения подгрупп пациентов с похожими особенностями и индивидуального подбора лечения. Прогнозирование течения болезни, оценка рисков, определение лечения. Анализ медицинских изображений и сигналов с использованием глубокого обучения.
Однако нужно иметь в виду, что при использовании методов машинного обучения в задачах медицинской диагностики могут возникать различные трудности. Так на качество решений существенно может повлиять недостаточный объем качественных данных для обучения моделей, поскольку многие медицинские данные конфиденциальны и их сбор требует больших усилий. В некоторых случаях возникает необходимость переобучения модели, когда она начинает лучше работать с обучающей выборкой, но плохо генерализуется на новые данные. Бывает возникает необходимость постоянного обновления системы по мере поступления новых знаний и данных. [1-4].
Учитывая перечисленные проблемы в данной работе предлагается использовать логические методы для построения модели диагностики поскольку построенные на логических правилах и ограничениях модели, более понятны и прозрачны для врачей/специалистов по сравнению с "черными ящиками" глубокого обучения. Качество - логические методы позволяют учитывать экспертные знания и делать выводы по неполным данным, при нейронных сетях требуется большой объем данных. Логические модели легко корректировать и дополнять по мере получения новых знаний, в отличие от регрессии/MLP.
1. Материалы и методы
Целью исследования является создание модели машинного обучения для поддержки диагностики гастрита на основе имеющихся данных о пациентах.
Гастрит - это распространенное заболевание, которое влияет на до 20% взрослого населения в развитых странах, а также наблюдается высокий уровень заболеваемости среди детей. Для точного определения хронического гастрита требуется проведение гистологического исследования биоптатов слизистой оболочки желудка, поскольку это позволяет выявить морфологические изменения, в то время как клиническая картина может быть неинформативной.
В 1990 году на IX Международном конгрессе гастроэнтерологов была принята Сиднейская система классификации гастритов. В 1996 году был опубликован окончательный вариант модифицированной Сиднейской системы, известный как "Классификация и градация гастрита. Модифицированная Сиднейская система". Согласно этой классификации, выделяются три основные категории гастритов: острый, хронический и особые формы.
Для нашего исследования мы использовали результаты гистологического исследования гастробиопсий 132 пациентов, проведенного в период с 2019 по 2022 год в Патологоанатомическом бюро, принадлежащем Государственному учреждению здравоохранения. Эти данные представляют собой ценный исходный материал для нашего исследования. Они позволяют нам анализировать и изучать различные патологические состояния желудка, выявлять связи между различными факторами и патологиями, и разрабатывать модели и алгоритмы диагностики на основе этих данных.
Использование результатов гистологического исследования в качестве основы для обучающей выборки обеспечивает нам возможность создать надежную и информативную модель, которая может быть применена в будущих исследованиях и клинической практике для более точной и эффективной диагностики патологий желудка. Это поможет улучшить процесс диагностики и разработать более эффективные методы лечения гастрита.
Необходимо построить алгоритм, способный классифицировать новых пациентов по этим данным и определять вероятный диагноз, чтобы помочь врачам в диагностике.
Учитывая небольшой объем данных, выбран логический подход машинного обучения, имеется ввиду логика наука о правильных рассуждениях независимо от области ее применения.
В данной задаче такой подход ряд преимуществ по сравнению с другими методами это легкая интерпретируемость и объяснимость полученных моделей, возможность эффективной работы с небольшими выборками, интеграция экспертных знаний и правил, лучшая работа с шумами и выбросами в данных.
Модель будет представлена в виде набора логических правил, позволяющих на основе симптомов и результатов обследования определять наиболее вероятный диагноз гастрита. Это облегчит работу врачей [5-6].
В качестве иллюстрации приведен фрагмент стандартизированной формы на рисунке 1, содержащей перечень симптомов и результатов обследований пациентов, которые учитывались при установлении диагноза гастрита.
Данная форма использовалась для фиксации клинической картины конкретного пациента и является частью исходных данных, на основании которых будет обучена предлагаемая модель. Заполнение такой формы врачом позволяет структурировать информацию о пациенте и симптомах заболевания.
.
Рисунок 1. Фрагмент анкеты вводимых данных
Математическая постановка: необходимо найти функцию 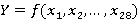 из 28 переменных, которая определена в 132 точках, область определения каждой переменной имеет разброс от 2 до 4 вариантов. Необходимо восстановить значение функции в других запрошенных точках. из 28 переменных, которая определена в 132 точках, область определения каждой переменной имеет разброс от 2 до 4 вариантов. Необходимо восстановить значение функции в других запрошенных точках.
Решение заключается в извлечении закономерностей из этих имеющихся примеров с установленным диагнозом и построении модели, основанной на анализе данных прошлых случаев.
Модель должна учитывать характеристики предыдущих пациентов, связь симптомов с диагнозом, и на основании этого быть способной классифицировать новые случаи.
Таким образом, задача формулируется как извлечение знаний из имеющегося набора решённых ранее аналогичных задач с целью прогнозирования решений для новых задач такого же класса.
И тогда 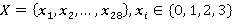 , –набор симптомов, диагностируемых заболеваний. , –набор симптомов, диагностируемых заболеваний.  – возможные диагнозы, каждый диагноз характеризуется соответствующим набором симптомов – возможные диагнозы, каждый диагноз характеризуется соответствующим набором симптомов 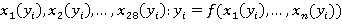 . .
Это может быть представленов следующем виде:
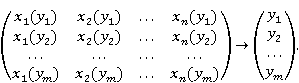
Нужно учитывать, что опытный специалист может предоставить информацию о диагностике гастрита, основанную на клиническом мышлении, которая может быть более полной и объективной по сравнению с автоматическим анализом данных. Тем не менее, формализованный логический подход позволяет выявить объективные статистические закономерности в данных и выделить наиболее значимые признаки для постановки диагноза.
При этом необходимо учитывать ценный практический опыт врачей и их экспертные знания о возможностях диагностики [7]. Наилучших результатов можно добиться, если комбинировать логический анализ данных с экспертизой медицинских специалистов. Это позволит разработать модель, основанную как на статистических закономерностях, так и на глубоких познаниях в области. Это приведёт к более точному пониманию процесса диагностики гастрита [8].
2. Результаты
В задачах медицинской диагностики часто приходится работать с неполной и противоречивой информацией. Логический анализ данных позволяет выделить как явные, так и скрытые закономерности, установленные статистически. Это дает возможность определить минимально достаточный набор признаков для объяснения всех наблюдаемых закономерностей.
Под непосредственным руководством врачей была разработана карта гистологического исследования (КГИ)
КГИ представляет собой инструмент для диагностики и анализа патологических состояний, разработанный совместно с врачами-патологоанатомами. Она состоит из двух частей:
Первая часть содержит информацию о пациенте, такую как фамилия, инициалы, пол, возраст, а также дата и номер исследования. Она также включает 28 диагностических признаков, которые устанавливаются во время гистологического исследования. Эти признаки организованы в определенной последовательности и представляют собой вариант первоначального алгоритма диагностики. Врач, проводящий исследование, фиксирует значения этих признаков в КГИ в строгой последовательности.
Вторая часть, называемая "Диагноз", содержит основные целевые признаки. Главный целевой признак - это сам диагноз, который может быть одним из трех значений: "норма", "хронический поверхностный гастрит (ХГП)" или "хронический атрофический гастрит (ХГА)". В зависимости от выбранного диагноза, возможно включение до 9 дополнительных признаков, таких как топография, этиология и активность.
КГИ позволяет систематизировать и стандартизировать процесс диагностики гистологических образцов и обеспечивает единый подход к оценке и классификации патологических состояний. Он предоставляет врачам полную информацию о пациентах и их гистологических данных, что способствует более точному и надежному диагнозу. КГИ также может быть использован в исследованиях и анализе данных для выявления связей между различными признаками и патологическими состояниями.
Такая модель будет более компактной и достоверной по сравнению с исходным набором данных. Она также обладает большей надежностью и быстротой обработки.
Система правил считается полной, если на ее основе можно воспроизвести все имеющиеся решения.
Группу диагнозов, обособленных по общим признакам или симптомам, удобно обозначать как класс.
Целью является построение такой модели на основе статистического анализа наличных медицинских данных.
Каждый диагноз может быть представителем одного или нескольких классов, причем каждый класс определяется набором схожих симптомов [9].
Логический анализ данных позволяет выявить закономерности в них и получить набор логических утверждений (правил), которые целиком описывают эти закономерности.
Это дает возможность классифицировать существующие диагнозы и разделить их на группы в зависимости от сходства симптомов.
Для каждого конкретного пациента можно сформулировать детерминированное условие (правило), устанавливающее взаимосвязь между наличием определенной комбинации симптомов и конкретным диагнозом.
.
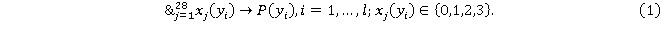
Это общее правило продукции, где предикат 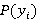 принимает значение true, т.е. принимает значение true, т.е. 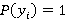 , если , если 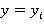 и и 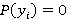 , если , если  . .
Данное правило может быть записано в другой форме:

Обобщающая модель для имеющегося набора данных может быть построена как логическое умножение (конъюнкция) всех индивидуальных правил классификации. То есть мы получим единое логическое выражение, учитывающее все возможные варианты соответствия комбинации признаков и диагнозов для всех объектов в выборке. Это позволит описать в виде единой функции зависимость между признаками и диагнозами для всего множества данных, объединив все частные правила в целостную модель. Полученная таким образом конъюнктивная функция будет в полной мере учитывать взаимосвязи, присущие рассматриваемому набору медицинских данных.
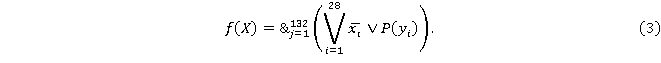
Построенная модель позволяет исключать несущественные признаки и разделять данные на классы по диагнозам, при этом один и тот же диагноз может быть характеризован различными комбинациями симптомов. В итоге получается логическое выражение из m+n переменных, где m - количество пациентов, а n - количество признаков.
Такая модель устанавливает правила соответствия комбинаций признаков и диагнозов, за исключением случаев, когда уже имеющиеся правила отрицаются. Она будет верна для всех действительных комбинаций признаков и диагнозов и неверна только если какие-то комбинации отрицают установленные ранее зависимости. Модель легко модифицировать, добавляя новые правила с помощью логического умножения. Это позволяет учитывать дополнительные данные или ситуации. Таким образом получается гибкая система, способная корректироваться и расширяться [10].
Данную логическую модель можно представить в виде рекурсивной функции. При этом каждое конкретное правило может вызывать другие правила или вспомогательные подфункции для установления окончательного диагноза. Такая иерархическая структура обеспечивает большую гибкость и эффективность обработки данных, поскольку позволяет принимать решения на основании цепочек выводов. Благодаря возможности модификации и расширения функции, а также применению рекурсивного формата, можно создавать адаптивные системы диагностики.
Они способны учитывать различные комбинации симптомов и принимать более точные и обоснованные решения по выявлению наиболее вероятного диагноза. Такая архитектура обеспечивает гибкость и способность постоянного совершенствования модели при поступлении новых данных.
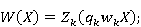


Где W(X) – моделируемая функция,  – характеристика объектов в текущий момент, – характеристика объектов в текущий момент, 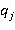 – состояние системы в текущий момент [12]. – состояние системы в текущий момент [12].
Если логическая функция представлена в виде минимизированной дизъюнктивной нормальной формы (МДНФ), она позволит компактно описать данные.В такой функции будут зашифрованы возможные варианты диагнозов; классы диагнозов, объединяющие их на основе сходства симптомов; комбинации признаков, не характерные для рассматриваемых диагнозов.
Преимуществом МДНФ является компактное и однозначное представление знаний. Это позволит сократить размер модели [11].
Фрагмент внутреннего программного представления продемонстрирован на рисунке 2
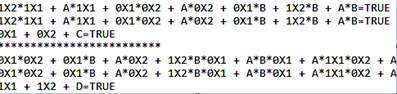
Рисунок 2. Фрагмент программного представление функции
При больших объемах данных прямое представление в виде ДНФ может стать громоздким. Поэтому целесообразно использовать приведенный ниже алгоритм.
3. Обсуждение
Данные о каждом пациенте представлены в виде таблицы, где столбцы соответствуют вопросам анкеты и возможным ответам, строки - пациентам и группам (классам) пациентов и их диагнозам. Значения симптомов и результатов обследования для каждого пациента записываются в соответствующие ячейки таблицы. Диагнозы кодируются цифрами и также помещаются в таблицу, в столбцы, соответствующие характеристикам данного пациента. Используются k-значные логические предикаты для описания зависимостей между симптомами и диагнозами. Эти предикаты формализуются в виде системы продуктивных правил отношений данных - симптомов к диагнозам.
Такая структуризация позволяет формализовать знания о зависимостях в рамках задачи распознавания диагнозов гастрита.
Набор симптомов 1 → Решение 1,
Набор симптомов 2 → Решение 2,
...
Набор симптомов м → Решение м.
Важно отметить, что одно и то же решение может произойти из разных наборов входных данных.
Во-первых, построенная система продуктивных правил (импликативных высказываний) может быть преобразована в оптимальное логическое выражение с учетом логических функций.
Это позволяет удалить избыточную информацию и выявить все возможные эквивалентные классы решений. Таким образом можно выделить скрытые закономерности в данных.
Описание программы:
Данная программа реализует описанный ранее алгоритм и состоит из двух исполняемых модулей:
Модуль 1: Расшифровка базы данных и анализ результатов.
Этот модуль выполняет расшифровку базы данных с использованием словаря.
Загружает симптомы и диагнозы в форме вопросно-ответных пар.
Анализирует результаты с использованием описанного алгоритма.
Модуль 2: Создание базы знаний Knoyledge.
Этот модуль программы выполняет функции по формированию и совершенствованию базы знаний. На основании информации из исходных данных создает начальную версию системы знаний. Обеспечивает уточнение и пополнение знаний уже существующей базы, может оптимизировать объем хранимой информации в зависимости от заданного уровня приближения
[12,13].
Для получения результата диагностики с заданной точностью необходимо заполнить все поля, указанные на рисунке 1.
Если заданная точность невозможна, это будет отображено в соответствующем сообщении, как показано на рисунке 3.
 
Рисунок 3. Результат диагностики
Заключение
В ходе исследования была разработана программная система для диагностики гастрита на основе логического анализа медицинских данных.
Предложенный метод анализа позволяет выявлять скрытые зависимости, классифицировать данные и выделить уникальные черты каждого диагноза. В отличие от нейронных сетей, логический подход более интерпретируем и не требует дополнительного обучения.
Логические алгоритмы являются эффективным инструментом для интеллектуального анализа данных. Они рассматривают исходную информацию как совокупность общих закономерностей, из которых можно выделить минимально достаточный набор правил для объяснения всех наблюдений. Эти правила также позволяют лучше понять изучаемые процессы.
Разработанная система может стать полезным инструментом для врачей-гастроэнтерологов, обеспечивая принятие обоснованных решений на основе логического осмысления данных иформирования интегративного представления о проблеме диагностики.
Библиография
1. Журавлёв Ю. И. Об алгебраическом подходе к решению задач распознавания или классификации // Проблемы кибернетики. 1978. Т. 33. С. 5–68.
2. Шибзухов З.М. Корректные алгоритмы агрегирования операций // Распознавание образов и анализ изображений. 2014. № 3 – 24. C. 377-382.
3. Ashley I. Naimi, Laura B. Balzer Multilevel generalization: an introduction to super learning // European Journal of Epidemiology. 2018. Vol. 33. P. 459–464.
4. Haoxiang, Wang, Smith S. Big data analysis and perturbation using a data mining algorithm // Journal of Soft Computing Paradigm. 2021. №. 3 – 01. P. 19-28.
5. Joe MrK, Vijesh, Jennifer S. Raj User Recommendation System Dependent on Location-Based Orientation Context // Journal of Trends in Computer Science and Smart Technology. 2021. № 3-01. P. 14-23.
6. Grabisch M., Marichal J-L, Pap E. Aggregation functions // Cambridge University Press. 2009. Vol. 127.
7. Calvo T, Belyakov G. Aggregating functions based on penalties // Fuzzy sets and systems. 2010. № 10-161. P. 1420-1436.
8. Mesiar R, Komornikova M, Kolesarova A, Calvo T. Fuzzy aggregation functions: a revision // Sets and their extensions: representation, aggregation and models. Springer-Verlag, Berlin, 2008.
9. Yang F, Yang Zh, Cohen W.W. Differentiable learning of logical rules for reasoning in the knowledge base // Advances in the field of neural information processing systems. 2017. P. 2320-2329
10. Akhlakur R., Sumaira T. Ensemble classifiers and their applications: a review //International Journal of Computer Trends and Technologies. 2014. Vol. 10. P. 31-35
11. Lyutikova L.A., Shmatova E.V. Algorithm for constructing logical operations to identify patterns in data // E3S Web of Conferences, Moscow, 25–27 ноября 2020 года. – Moscow, 2020. Vol. 224, P. 01009.
References
1. Zhuravljov, Ju. I. (1978). Ob algebraicheskom podhode k resheniju zadach raspoznavanija ili klassifikacii. Problemy kibernetiki, 33, 5–68.
2. Shibzukhov, Z.M. (2014). Correct Aggregation Operatios with Algorithms. Pattern Recognition and Image Analysis, 24(3), 377-382.
3. Naimi, A. I. & Balzer L.A. (2018). Multilevel generalization: an introduction to super learning. European Journal of Epidemiology, 33, 459-464.
4. Haoxiang, W. & Smith S. (2021). Big data analysis and perturbation using a data mining algorithm. Journal of Soft Computing Paradigm, 3–01, 19-28.
5. Joe, M. & Vijesh, J. S. (2021). User Recommendation System Dependent on Location-Based Orientation Context. Journal of Trends in Computer Science and Smart Technology, 3-01, 14-23.
6. Grabisch, M. & Marichal, J.L. & Pap, E. (2009). Aggregation functions. Cambridge University Press, 127,13-27.
7. Calvo, T. & Belyakov, G. (2010). Aggregating functions based on penalties. Fuzzy sets and systems, 10-161, 1420-1436.
8. Mesiar, R., Komornikova, M., Kolesarova, A. & Calvo, T. (2008). Fuzzy aggregation functions: a revision. Sets and their extensions: representation, aggregation and models. Berlin:Springer-Verlag.
9. Yang, F. & Yang, Zh. & Cohen W.W. (2017). Differentiable learning of logical rules for reasoning in the knowledge base. Advances in the field of neural information processing system, 3, 2320-2329.
10. Akhlakur, R. & Sumaira, T. (2014). Ensemble classifiers and their applications: a review. International Journal of Computer Trends and Technologies, 10, 31-35.
11. Lyutikova, L.A. & Shmatova, E.V. (2020). Algorithm for constructing logical operations to identify patterns in data. E3S Web of Conferences, 3, 217-222.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
В данной статье речь идет о возможностях использования искусственного интеллекта в целях медицинской диагностики. Автор зачем-то пользуется термином «машинное обучение», который к настоящему времени морально устарел. Но не в этом суть. Дело в том, что такая работа, действительно, нужна и она важна. И самое главное, что внедрение искусственного интеллекта в практику медицинской диагностики остановить невозможно, нравится это кому-то или нет. Процесс идет и в этом отношении важно определить приоритеты.
Автор пишет, что медицинская диагностика активно использует методы машинного обучения, которые позволяют эффективно анализировать данные и поддерживать процесс постановки диагноза. Да, это так. Предлагается использовать логические методы для построения модели диагностики, поскольку построенные на логических правилах и ограничениях модели, более понятны и прозрачны для врачей/специалистов по сравнению с «черными ящиками» глубокого обучения. В данном месте очевидна подмена понятий. Говоря об использовании логических методов, автор имеет в виду логику искусственного интеллекта. Но есть еще понятие диагностической логики в качестве процесса определения этиологии и патогенеза заболевания, дифференциально-диагностических отличий, индивидуальных особенностей патологического процесса и др. Это врачебная логика. Поэтому автор в этой статье пишет не о той логике, которой обучают в медицинских вузах. В этом конфликт.
Поэтому все дальнейшее изложение материала в данном тексте надо понимать, как процесс построения диагностического машинного алгоритма, который может иметь какое-то отношение к медицинской диагностике. А может и не иметь. Такие возможности относятся к дополнительным и вспомогательным средствам диагностики. Учитывая их в общем диагностическом процессе, врачу важно не ошибиться. Но о рисках использования таких машинных диагностических моделей пока в литературе данных нет. Все пишут об одном и том же, как и автор данной статьи, что такие модели только облегчат работу врача, ошибочно полагая, что врач очень сильно устает от диагностики. Это не соответствует действительности. Врач устает не от диагностики.
Тем не менее, целью данного исследования «является создание модели машинного обучения для поддержки диагностики гастрита на основе имеющихся данных о пациентах». Мысль автора понятна и с такой формулировкой цели можно согласиться в принципе.
Далее по тексту сказано, что было выделено 17 типов гастрита. Какие это 17 типов? Зачем они? Это по запросу врачей или по инициативе разработчика модели? Врачам не надо навязывать какие-то новые типы гастритов и таким образом обязывать их перестраивать диагностический процесс с учетом машинной логики. Должно быть ровно все наоборот.
А автор уже пишет, что «необходимо построить алгоритм, способный классифицировать новых пациентов по этим данным и определять вероятный диагноз, чтобы помочь врачам в диагностике». По каким это «этим данным»? Это по этим 17 типам? А далее, следовательно, необходимо направить врачей на обучение знаниям машинной логики?
Такой подход не верен в принципе. И это потому, что автор не опирается на какие-либо разумные методологические принципы медицинской диагностики. Врачам-диагностам надо помогать, а не мешать.
Приводимые ниже формулы для потенциального читателя никакого интереса не представляют и напрасно автор их привел по тексту. Какого-либо аргументирующего значения они не имеют. Статьи с таким содержанием необходимо рассматривать в специализированных журналах.
Но все-таки надо отдать должное автору в том смысле, что он придерживается правильного понимания соотношений человека и машины. Так, в статье отмечено, что необходимо учитывать, что «опытный специалист может предоставить информацию о диагностике гастрита, основанную на клиническом мышлении, которая может быть более полной и объективной по сравнению с автоматическим анализом данных». Тем не менее, формализованный логический подход позволяет выявить «объективные статистические закономерности в данных и выделить наиболее значимые признаки для постановки диагноза. При этом необходимо учитывать ценный практический опыт врачей и их экспертные знания о возможностях диагностики». Так правильно пишет автор и это свидетельствует о том, что он, скорее всего, сумеет найти взаимопонимание с медицинским сообществом в вопросах не только применения машинных моделей в диагностическом процессе, но, что еще более важно, в процессе разработки таких моделей.
В этом смысле открывается перспектива психологического осмысления критических аспектов данного процесса. Необходимо учитывать здоровый консерватизм системы медицинской диагностики и необходимость внедрения в нее новых моделей, основанных на логике машинной логики. Все это будет способствовать рационализации диагностического процесса за счет расстановки диагностических приоритетов. Какой будет эта расстановка, сказать невозможно до обобщения опыта применения диагностических машинных алгоритмов. Рецензент, кстати, не исключает, что в ряде случаев использование машинного интеллекта вполне может быть приоритетным.
Поэтому данную статью можно рекомендовать к опубликованию после доработки текста и переработки библиографического списка, включив в него источники, которые более понятны не только врачам, но и психологам.
Результаты процедуры повторного рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Предметом исследования в рецензируемой статье выступает логическое моделирование и его применение для анализа и классификации медицинских данных с целью диагностики.
Методология исследования базируется на обработке статистических данных о результатах гистологического исследования гастробиопсий 132 пациентов, проведенного в период с 2019 по 2022 год в Патологоанатомическом бюро, принадлежащем Государственному учреждению здравоохранения, применении методов моделирования и машинного обучения.
Актуальность работы авторы справедливо связывают с тем, что методы машинного обучения эффективно анализировать данные и поддерживать процесс постановки медицинского диагноза, а применяемые алгоритмы самостоятельно находят признаки и строят модели на основе обучающих данных.
Научная новизна рецензируемого исследования, по мнению рецензента, состоит в разработанной авторами статьи модели машинного обучения для поддержки диагностики гастрита для диагностики гастрита на основе логического анализа медицинских данных.
В статье структурно выделены следующие разделы: Введение, Материалы и методы, Результаты, Обсуждение, Заключение, Библиография.
В статье приведено описание построения алгоритма, способного классифицировать новых пациентов по данным результатов гистологического исследования, используемым в качестве основы для обучающей выборки и определения диагноза. Математическая постановка задачи сводится к нахождению функцию 28 переменных, область определения каждой из которых имеет разброс от 2 до 4 вариантов, по 132 точкам и восстановлению значений функции в других запрошенных точках. Авторы считают, что логический анализ данных позволяет выявить закономерности в них и получить набор логических утверждений, которые целиком описывают эти закономерности, что дает возможность классифицировать существующие диагнозы и разделить их на группы в зависимости от сходства симптомов. Модель машинного обучения позволяет исключать несущественные признаки и разделять данные на классы по диагнозам.
Предложенная авторами программа включает два модуля: «Расшифровка базы данных и анализ результатов», а также «Создание базы знаний». Текст статьи иллюстрирован тремя рисунками: «Фрагмент анкеты вводимых данных», «Фрагмент программного представление функции», «Результат диагностики», содержит четыре формулы. В Заключении сделаны выводы о том, что Логические алгоритмы являются эффективным инструментом для интеллектуального анализа данных, а разработанная система может стать полезным инструментом для врачей-гастроэнтерологов, обеспечивая принятие обоснованных решений.
Библиографический список включает 11 источников – публикации зарубежных и отечественных ученых по теме статьи, на которые в тексте имеются адресные ссылки, подтверждающие наличие апелляции к оппонентам.
В качестве замечания следует отметить, что в тексте встречаются опечатки, например, «иформирования» в заключительном предложении статьи.
Статья отражает результаты проведенного авторами исследования, соответствует направлению журнала «Программные системы и вычислительные методы», содержит элементы научной новизны и практической значимости, может вызвать интерес у читателей, рекомендуется к опубликованию.
|
 Рус
Рус










