|
Налоги и налогообложение
Правильная ссылка на статью:
Харитонова А.Е.
Прогнозирование налоговой нагрузки сельскохозяйственных предприятий методами машинного обучения
// Налоги и налогообложение.
2023. № 4.
С. 28-38.
DOI: 10.7256/2454-065X.2023.4.43917 EDN: VUBDLU URL: https://nbpublish.com/library_read_article.php?id=43917
Прогнозирование налоговой нагрузки сельскохозяйственных предприятий методами машинного обучения
Харитонова Анна Евгеньевна
ORCID: 0000-0001-8480-6279
кандидат экономических наук
доцент, Департамент налогов и налогового администрирования, Финансовый университет
127083, Россия, Москва, г. Москва, ул. Верхняя Масловка, 15
Kharitonova Anna Evgen'evna
PhD in Economics
Associate Professor, Department of Taxes and Tax Administration, Financial University
127083, Russia, Moscow, Moscow, Verkhnyaya Maslovka str., 15

|
kharitonova.ae@yandex.ru
|
|
 |
|
DOI: 10.7256/2454-065X.2023.4.43917
EDN: VUBDLU
Дата направления статьи в редакцию:
28-08-2023
Дата публикации:
05-09-2023
Аннотация:
В статье проанализированы данные совокупности сельскохозяйственных предприятий и построены модели машинного обучения для прогнозирования налоговой нагрузки. Предметом настоящего исследования являются система статистических показателей сельскохозяйственных предприятий, характеризующих уровень налоговой нагрузки. Целью исследования является прогнозирование налоговой нагрузки методами машинного обучения. Внедрение современных средств искусственного интеллекта представляют собой неотъемлемый и неизбежный процесс во всех сферах, в т.ч. и в налоговой среде. Для построения моделей были использованы методы машинного обучения: регрессионный анализ, дерево решений, случайный лес, градиентный бустинг. Были построены модели прогнозирования налоговой нагрузки в зависимости от комплекса факторов. Высокое качество моделей прогнозирования налоговой нагрузки позволит более точно оценивать финансовое состояние предприятий, проводить расчеты рентабельности, прогнозировать доходность и принимать обоснованные инвестиционные управленческие решения. В результате прогнозирования налоговой нагрузки лучшее качество оказалось у модели машинного обучения градиентного бустинга. В целом модель позволяет прогнозировать налоговую нагрузку лучше, чем традиционные эконометрические модели и давать прогнозы высокого качества. Внедрение современных инструментов прогнозирования, основанных на методах искусственного интеллекта, позволит получать высокоточные прогнозы при минимальных затратах времени, что повысит эффективность деятельности предприятий и уровень производства.
Ключевые слова:
налоговая нагрузка, налоговое планирование, налоговое прогнозирование, налоговый менеджмент, финансовый менеджмент, методы машинного обучения, дерево решений, случайный лес, градиентный бустинг, модели регрессии
Abstract: The article analyzes the data of a set of agricultural enterprises and builds machine learning models to predict the tax burden. The subject of this study is a system of statistical indicators of agricultural enterprises that characterize the level of tax burden. The purpose of the study is to predict the tax burden using machine learning methods. The introduction of modern artificial intelligence tools is an integral and inevitable process in all spheres, including in the tax environment. Machine learning methods were used to build models: regression analysis, decision tree, random forest, gradient boosting. Models of forecasting the tax burden depending on a set of factors were built. The high quality of tax burden forecasting models will make it possible to more accurately assess the financial condition of enterprises, calculate profitability, predict profitability and make informed investment management decisions. As a result of forecasting the tax burden, the gradient boosting machine learning model turned out to have the best quality. In general, the model allows you to predict the tax burden better than traditional econometric models and make high-quality forecasts. The introduction of modern forecasting tools based on artificial intelligence methods will allow obtaining highly accurate forecasts with minimal time, which will increase the efficiency of enterprises and the level of production.
Keywords: tax burden, tax planning, tax forecasting, tax management, financial management, machine learning methods, decision tree, random forest, gradient boosting, regression models
Введение
Между налоговыми органами и налогоплательщиками часто возникает конфликт интересов, так как целью первых является обеспечение бюджетов всех уровней максимальными поступлениями от уплаты налогов, а вторых – минимизация налоговых обязательств для максимизации своих доходов [1]. Именно поэтому установление оптимальной налоговой нагрузки для организаций способствует развитию их деятельности и повышению ими налоговой дисциплины. С другой стороны, налоговая нагрузка является значимым индикатором состояния экономики. Высокая налоговая нагрузка может оказывать отрицательное влияние на экономическую активность и инвестиции, в то время как низкая налоговая нагрузка может привести к недофинансированию государственного бюджета. Величина налоговой нагрузки зависит от конкретной налоговой системы, политики и приоритетов государственного регулирования [2]. В этой связи задача любого государства – определить оптимальный уровень налоговой нагрузки, позволяющий обеспечить паритет интересов бюджета и бизнеса.
Прогнозирование налоговой нагрузки имеет большую актуальность в современном мире, особенно в условиях нестабильной экономической ситуации и частых изменений в налоговом законодательстве. Государственным органам и органам местного самоуправления прогнозные значения налоговой нагрузки позволяют грамотно планировать свои бюджетные доходы и расходы на будущий период. Это важно для разработки эффективных стратегий финансирования социальных программ, обороны, образования и других общественных нужд. Правительству и другим интересующимся сторонам – анализировать текущую ситуацию и принимать обоснованные решения по налоговой политике. Прогнозы помогают определить оптимальные ставки налогов, исследовать влияние изменений налогового законодательства и оценивать результативность налоговых стимулов и льгот. Кроме того, при сравнении фактических показателей налоговой нагрузки экономического субъекта со среднеотраслевыми налоговые службы выявляют потенциальные случаи недекларирования доходов или уклонения от уплаты налогов. Это способствует справедливому распределению налогового бремени и позволяет государству собирать необходимые доходы для обеспечения своих функций и обязательств. Актуальность оценки и прогнозирования налоговой нагрузки для предпринимателей обосновывается возможностью планирования своей деятельности и расчета бизнес-показателей. Знание предполагаемой налоговой нагрузки позволяет более точно оценивать финансовое состояние предприятия, проводить расчеты рентабельности, прогнозировать доходность и принимать обоснованные инвестиционные решения [3].
В целом, прогнозирование налоговой нагрузки является важным инструментом для государства, бизнеса и общества в целом. Оно позволяет выявлять потенциальные проблемы, предотвращать злоупотребления и оптимизировать состояние налоговой системы для обеспечения устойчивого экономического развития и социального благополучия.
Применение современных инструментов и программных средств для прогнозирования налоговой нагрузки повысит качество получаемых значений, сократит затраты времени на обработку данных и построение моделей и повысит эффективность экономической деятельности предприятий.
Литературный обзор
Современное состояние экономики требует повышения качества прогнозирования как на макроуровне, так и на уровне отдельного предприятия. В постпандемийных и санкционных условиях необходимо уметь качественно и оперативно прогнозировать риски для грамотного управления в условиях сложных обстоятельств и неопределенностей в экономической деятельности [9].
В условиях неопределенности и недостатка информации многие исследователи используют в своих работах экспертный метод. Так, Трещевский Ю.И., Кособуцкая А.Ю. и Опойкова Е.А. использовали экспертный метод прогнозирования влияния экономических антисанкционных мер на экономику региона[10]. Также в работе Зуевой Т.И. применен экспертный метод при прогнозировании параметров инновационного развития предприятий [6]. Однако экспертные методы довольно сложно адаптировать при изменении условий и обновлении данных (особенно актуально для налоговой среды), что требует применения новых инструментов и средств анализа.
Для построение моделей прогнозирования традиционным является применение статистических методов. Так, Храмцова Т.Г. и Храмцова О.О. используют статистические методы для прогнозирования финансовых результатов предприятия.
Одним из наиболее популярных методов прогнозирования является корреляционно-регрессионный анализ. Например, Костина З.А. и Машенцева Г.А. использовали корреляционно-регрессионный анализ для прогнозирования налоговых доходов бюджета субъекта Российской Федерации [13], Кузина Е.И. – для прогнозирования налоговых поступлений Рязанской области [14].
Яблоков Д.Ю. сравнивает в своем исследовании эффективность прогнозирования методом ARIMA и с помощью нейронной сети и отдает предпочтение последнему с достаточной убедительностью [15]. Методы искусственного интеллекта активно применяются для прогнозирования банкротства предприятий и финансового состояния [16, 17], а в работе Иваньковой С.С. используется модель дерева решений для оценки риска банкротства [18].
Методы искусственного интеллекта используются для прогнозирования и в аграрном секторе экономики. Возможности применения искусственного интеллекта и нейросетевых технологий в цифровой платформе прорывного развития российского АПК рассмотрены в работе Илышова А.П. и Толмачева О.М. [19]. Методы машинного обучения также применяются для прогнозирования уровня оснащенности сельскохозяйственных предприятий [20, 21].
Тем не менее, как показал проведенный обзор литературы, сфера применения методов машинного обучения в прогнозировании налоговой нагрузки не изучена, отсутствует сопоставление результатов таких методов с классическим корреляционно-регрессионным анализом, чему и посвящена практическая часть исследования.
Материалы и методы исследования
Входной информацией для обработки послужили данные бухгалтерской отчетности по 20000 сельскохозяйственных предприятий России за 2021 год. Исходная размерность входных данных составила 20000 строк на 138 столбцов. В данных присутствуют пропущенные значения, качественные переменные и выбросы. На этапе предварительной обработки данных была проведена работа с пропущенными значениями. Для ряда показателей формы 1-2 бухгалтерской отчетности данные вносятся в обязательном порядке, поэтому пропуск означает, что этот показатель равен 0. Для оставшихся столбцов удалены показатели, у которых более 5% пропусков, далее удалены все строки в которых есть хотя бы 1 пропуск. В результате удаления из выборки исключены 2179 предприятий.
С точки зрения статистики целесообразно сравнивать единицы совокупности по относительным показателям. Данные, характеризующие экономическую деятельность, целесообразно соотнести с ресурсами предприятия. Для сельскохозяйственных предприятий целесообразно всего соотносить данные с площадью сельскохозяйственных угодий. Однако в исходных данных отсутствует данный показатель, поэтому соотнесем данные со среднегодовой численностью работников, а также досчитаем возможные относительные показатели деятельности предприятий:
- Налоговая нагрузка, %;
- Возраст компании, лет;
- Чистые активы на 1 работника, руб.;
- Кредиторская задолженность на 1 работника, руб.;
- Фондовооруженность, руб./чел.;
- Доля внеоборотных активов в общих;
- Коэффициент оборачиваемости совокупных активов;
- Коэффициент концентрации собственного капитала (автономии);
- Доля себестоимости как процент от выручки.
Перед выявлением факторов налоговой нагрузки проведена диагностика данных на наличие выбросов, это позволило сделать совокупность однородной. Так, по налоговой нагрузке выбросы не были выявлены (рисунок 1), однако по ряду других показателей выбросы присутствовали в данных. С помощью правила трех сигм удалены все предприятия, не попадающие в данный интервал.
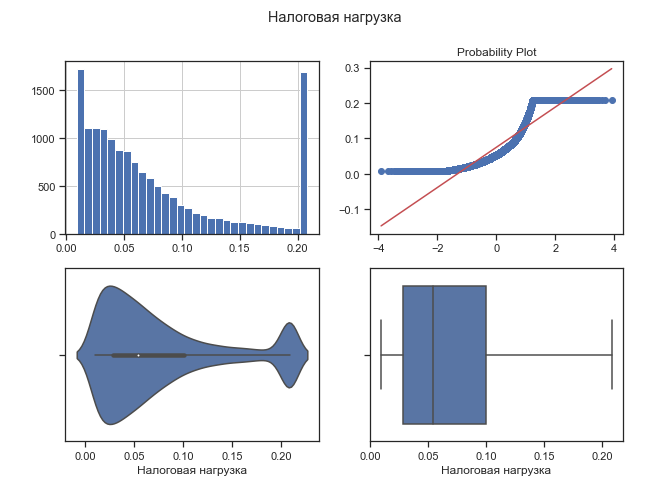
Рисунок 1 – Графики диагностики выбросов в исходных данных
По результату избавления от пропущенных значений и выбросов в совокупности осталось 15015 предприятий.
В качестве методов исследования были использованы модели машинного обучения. Для решения задач регрессии в исследовании использованы следующие алгоритмы:
· Деревья решений;
· Случайный лес;
· Градиентный бустинг;
· Нейронные сети.
Дерево решений (Decision Tree) – двоичная рекурсивная непараметрическая процедура, позволяющая обрабатывать количественные и качественные входные и выходные величины в их исходной, необработанной форме [4]. Цель состоит в том, чтобы создать модель, которая предсказывает значение целевой переменной, изучая простые правила принятия решений, выведенные из характеристик данных. Каждый узел дерева - это проверка для различных условий по определенной переменной, ветви дерева - это результат проверки, а конечные узлы - это решение, принятое после вычисления всех атрибутов [5]. Для прогнозирования налоговой нагрузки дерево решений может быть использован как алгоритм поиска наиболее значимых факторов с целью получения наиболее точного прогноза.
Бустинг (AdaBoost) – это процедура построения алгоритмов, когда каждый следующий старается компенсировать недостатки предыдущих. Он создает модель прогнозирования в виде ансамблей слабых моделей прогнозирования, обычно деревьев решений; строит модель поэтапно, обобщает их, позволяя оптимизировать произвольную дифференцируемую функцию потерь [6]. Для целей прогнозирования налоговой нагрузки градиентный бустинг дает прогнозы высокого качества на основе нетривиальных разбиений, выработанных алгоритмом дерево решений.
Случайный лес (Random Forest) –это алгоритм, который объединяет несколько деревьев решений на основе идеи ансамблевого обучения. Для формирования каждого дерева в ансамбле реализуется процедура бэггинга – случайный отбор с повторениями элементов обучающей выборки в обучающую подвыборку [7, 8]. Объединение деревьев позволяет получить более точные и стабильные прогнозы налоговой нагрузки при нелинейных и нетривиальных зависимостях.
В качестве инструмента обработки данных был использован язык программирования Python с дистрибутивом Anaconda в среде Jupyter Lab. Для загрузки и анализа данных были использованы следующие пакеты: numpy , pandas, seaborn, matplotlib, sklearn и tensorflow.
Результаты исследования
Для определения взаимосвязей между признаками построим тепловую карту коэффициентов корреляции (рисунок 2). Прямая линейная зависимость факторов на налоговую нагрузку отсутствует, что также подтверждается построением множественной линейной модели регрессии, коэффициент детерминации для которой составляет лишь 21%. Таким образом, прогнозировать налоговую нагрузку по данной модели нельзя. Для возможности прогнозирования и выявления нелинейных взаимосвязей между признаками построим модели машинного обучения.
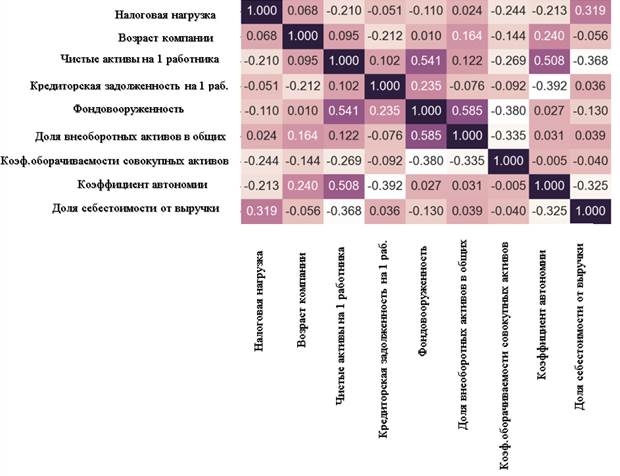
Рисунок 2 – Тепловая карта коэффициентов корреляции
Модель «Дерево решений» строит граф в виде структуры с узлами, в которых задаются условия, и листьях с возможными решениями. Для построения модели с наилучшими характеристиками был осуществлен подбор параметров с помощью функции GridSearchCV. В результате качество построенной модели оказалось недостаточно высоким. Коэффициент детерминации говорит о том, что всего 27,4% вариации налоговой нагрузки можно объяснить влиянием включенных в модель факторов. Также в качестве метрик качества построенных моделей рассмотрим среднюю ошибку и среднюю абсолютную ошибку. Средняя ошибка прогноза составила 0,04 при среднем значении признака 0,075. Средняя абсолютная ошибка между налоговой нагрузкой, предсказанными моделью, и фактической составляет 1,1%. Для целей прогнозирования данная модель не подходит из-за низкого коэффициента детерминации и высоких значений ошибок.
Модель «Случайный лес» строится на основе комитета деревьев решений и обычно показывает более высокое качество. Для построения модели с наилучшим качеством был также осуществлен подбор параметров. В результате коэффициент детерминации составил 43,4%, что говорит о том, что на 43,4% вариации налоговой нагрузки зависит от включенных в модель факторов. Средняя ошибка составила 0,03 при среднем значении признака 0,075, а средняя абсолютная ошибка между налоговой нагрузкой, предсказанными моделью, и фактической составляет 0,95%. В целом качество модели оказалось выше, чем по алгоритму «Дерево решений».
Для сравнения построим модель с помощью алгоритма градиентного бустинга, основанного на дереве решений. С целью поиска модели с лучшим качеством проводился побор параметров, в результате коэффициент детерминации составил 46,2%. Т.е. 46,2% вариации переменной (налоговой нагрузки) зависит от включенных в модель факторов. Сравним метрики качества построенных моделей (таблица 1). Наиболее высоким оказался коэффициент детерминации для модели градиентного бустинга, он выше модели «Случайный лес» на 2,9%. Также более высокое качество модели подтверждает средняя ошибка (0,033) и средняя относительная ошибка (0,847), которые ниже, чем по моделям «Дерево решений» и «Случайный лес». Для получения точных и достоверных прогнозов следует увеличивать коэффициент детерминации в моделях, однако по модели градиентного бустинга оценить возможные значения налоговой нагрузки возможно.
Таблица 1 – Оценка качества построенных моделей машинного обучения
|
Модель регрессии
|
Коэффициент детерминации (R2)
|
Средняя ошибка (MAE)
|
Средняя абсолютная ошибка (MAPE)
|
|
Модель «Дерево решений»
(DecisionTreeRegressor)
|
0,274
|
0,040
|
1,104
|
|
Модель «Случайный лес»
(RandomForestRegressor)
|
0,434
|
0,035
|
0,949
|
|
Модель «Градиентный бустинг»
(HistGradientBoostingRegressor)
|
0,463
|
0,033
|
0,847
|
По наилучшей модели из построенных сравним прогнозные значения налоговой нагрузки для трех случайно отобранных из выборки предприятий.Для первого предприятия прогнозируется налоговая нагрузка 7,6%, что выше фактического значения на 4,1%, т.е. погрешность достаточно высокая. Для второго предприятия прогнозируемая налоговая нагрузка составила 5,7% при фактическом уровне 3,9% (разность 1,8%). Для третьего предприятия прогноз составил 3,1% налоговой нагрузки, при фактическом уровне 6,7% (разность 3,1%). Таким образом следует отметить, что методы машинного обучения дают результаты лучше, чем традиционные регрессионные модели, однако для получения более качественных и достоверных прогнозов модели следует улучшать и дорабатывать. Одним из дальнейших путей повышения качества моделей может служить разделение предприятий на более однородные группы по результатам хозяйственной деятельности и построении моделей для каждой группы в отдельности. В целом использование методов машинного обучения является перспективным направлением для работы и использовании их в налоговом прогнозировании и выработке налоговой стратегии компании.
Выводы и предложенияВ процессе исследования проведена обработка данных 20000 сельскохозяйственных предприятий на языке программирования Python и построены модели прогнозирования налоговой нагрузки с помощью множественной линейной модели регрессии, дерева решений, случайного леса и градиентного бустинга. При сравнении моделей видно, что методы градиентного бустинга и случайного леса намного превосходят по метрикам качества модели линейной регрессии и дерева решений при одинаковом наборе входных предикторов. Таким образом можно отметить, что применение методов машинного обучения повышает качество прогнозирования, а потому они могут быть внедрены в деятельность предприятий.Возможности современных средств искусственного интеллекта позволяют при прочих равных условиях получать более достоверные и качественные прогнозы в сравнении с традиционными эконометрическими моделями. При этом использование специализированных на анализе языков программирования, таких как Python или R, позволят снизить затраты на предобработку данных и построение моделей, что позволит получать прогнозы для принятия оперативных решений для повышения экономической эффективности деятельности.Важно отметить, что представленный в настоящем исследовании методический подход может применяться не только экономическими субъектами при налоговом планировании и прогнозировании, но и налоговыми органами при определении критериев для выявления объектов пристального налогового контроля. В частности, построение моделей с применением методов машинного обучения позволит получить перечень зависимых индикаторов, которые могут быть рассмотрены налоговыми органами совместно с низким уровнем налоговой нагрузки при отборе организаций для целей выездного налогового контроля.
Библиография
1. Тихонова, А. В. Налоговая нагрузка и иные мотивы законопослушного поведения физических лиц // Экономика. Налоги. Право. – 2021. – Т. 14, № 2. – С. 169-178.
2. Медюха, Е. В. Влияние налоговой нагрузки на финансово-хозяйственную деятельность предприятия / Е. В. Медюха, Е. В. Артюшенко // Вектор экономики. – 2019. – № 10(40). – С. 14.
3. Налоги и налоговая система Российской Федерации / Гончаренко Л.И., Адвокатова А.С., Гончаренко А.Е., Зверева Т.В., Карпова Г.Н., Каширина М.В., Липатова И.В., Малкова Ю.В., Мандрощенко О.В., Мельникова Н.П., Мигашкина Е.С., Пинская М.Р., Пьянова М.В., Савина О.Н., Смирнов Д.А., Смирнова Е.Е., Тихонова А.В., Юшкова О.О.Учебник / Сер. 76 Высшее образование. (3-е изд., пер. и доп) Москва, 2023.
4. Wu X., Kumar V., Quinlan R., Ghosh J., Yang Q. Motoda H., Mclachlan G., Ng S.K.A., Liu B., Yu P., Zhou Z.-H., Steinbach M., Hand D., Steinberg D. Top 10 algorithms in data mining. Knowledge and Information Systems. – 2008. – Vol. 14. – pp. 1–37.
5. Nasteski, Vladimir. An overview of the supervised machine learning methods. Horizons.B. – 2017. – Volume 4. – P. 51-62.
6. Cравнение классических регрессионных моделей с моделями, построенными с помощью продвинутых методов машинного обучения / Шатров А.В., Пащенко Д.Э. // Advanced Science. 2019. № 1 (12). С. 24-28.
7. Biau, G. Analysis of a Random Forests Model / G. Biau // Journal of Machine Learning Research. – 2012. – Vol. 13. – P. 1063–1095.
8. Модели машинного обучения в задаче прогнозирования природно-ресурсного потенциала пермского края / Копотева А.В., Максимов А.А., Сиротина Н.А. // Вестник Южно-Уральского государственного университета. Серия: Компьютерные технологии, управление, радиоэлектроника. – 2021. – Т. 21. – № 4. – С. 126-136.
9. Полухина И.В. Анализ рисков и внутрихозяйственных резервов устойчивого развития организаций в условиях беспрецедентных экономических ограничений и новых реалиях конкуренции // Современная экономика: проблемы и решения. – 2022. – № 5 (149). – C. 125-142.
10. Прогнозирование влияния антисанкционных мер экономической политики на экономику региона / Трещевский Ю.И., Кособуцкая А.Ю., Опойкова Е.А. // Современная экономика: проблемы и решения. – 2022. – № 8 (152). – С. 8-25.
11. Зуева Т.И. Применение метода экспертных оценок при прогнозировании показателей инновационного потенциала предприятия // Московский экономический журнал. – 2020. – № 6. – С. 82.
12. Прогнозирование финансовых результатов на основе статистических методов / Храмцова Т.Г., Храмцова О.О. // Транспортное дело России. – 2021. – № 3. – С. 12-15.
13. Прогнозирование налоговых доходов бюджета субъекта Российской Федерации с использованием корреляционно-регрессионного анализа / Костина З.А., Машенцева Г.А. // Сибирская финансовая школа. – 2019. – № 5 (136). – С. 144-147.
14. Применение корреляционно-регрессионного анализа в прогнозировании налоговых поступлений Рязанской области / Кузина Е.И. // Вестник Волжского университета им. В.Н. Татищева. 2021. Т. 2. № 3 (48). С. 133-142.
15. Статистические методы налогового прогнозирования в условиях неопределенности внешней среды / Яблоков Д.Ю. // Проблемы экономики и управления в торговле и промышленности. – 2015. – № 2 (10). – С. 42-47.
16. Прогнозирования банкротства предприятий с использованием искусственного интеллекта / Апатова Н.В., Попов В.Б. // Научный вестник: финансы, банки, инвестиции. – 2020. – № 2 (51). – С. 113-120.
17. Использование машинного обучения в финансовом прогнозировании в банках / Виноградов А.С. // Актуальные вопросы современной экономики. – 2022. – № 5. – С. 705-710.
18. Оценка и анализ риска банкротства с использованием decision tree модели машинного обучения / Иванькова С.С. // Интерактивная наука. – 2022. – № 2 (67). – С. 44-46.
19. Искусственный интеллект и нейросетевые технологии в цифровой платформе прорывного развития российского АПК / Илышев А.П., Толмачев О.М. // Экономика и социум: современные модели развития. – 2019. – Т. 9. № 4 (26). – С. 492-507.
20. Forecasting the production of gross output in agricultural sector of the ryazan oblast / Khudyakova E., Nikanorov M., Bystrenina I., Cherevatova T., Sycheva I. // Estudios de Economía Aplicada. – 2021. – Т. 39. – № 6.
21. Проблемы анализа и прогнозирования уровня технической оснащенности сельскохозяйственных предприятий (на примере Рязанской области) / Худякова Е.В., Никаноров М.С., Бутырин В.В. // Бухучет в сельском хозяйстве. – 2021. – № 2. – С. 69-77.
References
1. Tikhonova, A.V. (2021). Tax burden and other motives for the law-abiding behavior of individuals. Economy. Taxes. Right, 14(2), 169-178.
2. Medyukha, E.V. & Artyushenko, E.V. (2019). The impact of the tax burden on the financial and economic activities of the enterprise. Vector of the economy, 10(40), 14.
3. Goncharenko, A.E., Zvereva, T.V., & Karpova, G.N. (Eds.). (2023). Taxes and the tax system of the Russian Federation. Textbook, Moscow.
4. Wu, X., Kumar, V., & Quinlan, R. (Eds.). (2008). Top 10 algorithms in data mining. Knowledge and Information Systems, 14, 1–37.
5. Nasteski, V. (2007). An overview of the supervised machine learning methods. Horizons, 4, 51-62.
6. Shatrov, A.V. & Pashchenko, D.E. (2019). Comparison of classical regression models with models built using advanced machine learning methods. Advanced Science, 1(12), 24-28.
7. Biau, G. (2012). Analysis of a Random Forests Model. Journal of Machine Learning Research, 13, 1063-1095.
8. Kopoteva, A.V., Maksimov, A.A. & Sirotina, N.A. (2021). Machine learning models in the problem of forecasting the natural resource potential of the Perm region. Bulletin of the South Ural State University. Series: Computer technologies, control, radio electronics, 21, 4, 126-136.
9. Polukhina, I.V. (2022). Analysis of risks and on-farm reserves of sustainable development of organizations in the context of unprecedented economic restrictions and new realities of competition. Modern Economics: Problems and Solutions, 5(149), 125-142.
10. Treshchevsky, Yu.I., Kosobutskaya, A.Yu. & Opoykova, E.A. (2022). Forecasting the impact of anti-sanction measures of economic policy on the regional economy. Modern economy: problems and solutions, 8(152), 8-25.
11. Zueva, T.I. (2020). Application of the method of expert assessments in predicting indicators of the innovative potential of an enterprise. Moscow Economic Journal, 6, 82.
12. Khramtsova, T.G. & Khramtsova, O.O. (2021). Forecasting financial results based on statistical methods, Transport business in Russia, 3, 12-15.
13. Kostina, Z.A. & Mashentseva, G.A. (2019). Forecasting tax revenues of the budget of the subject of the Russian Federation using correlation and regression analysis. Siberian Financial School, 5(136), 144-147.
14. Kuzina, E.I. (2021). Application of correlation-regression analysis in forecasting tax revenues in the Ryazan region. Bulletin of the Volga University V.N. Tatishchev, 2(3(48)), 133-142.
15. Yablokov, D.Yu. (2015). Statistical methods of tax forecasting in conditions of uncertainty of the external environment. Problems of economics and management in trade and industry, 2(10), 42-47.
16. Apatova, N.V. & Popov, V.B. (2020). Forecasting the bankruptcy of enterprises using artificial intelligence. Scientific Bulletin: finance, banks, investments, 2(51), 113-120.
17. Vinogradov, A.S. (2022). The use of machine learning in financial forecasting in banks. Topical issues of modern economics, 5, 705-710.
18. Ivankova, S.S. (2022). Evaluation and analysis of bankruptcy risk using a decision tree model of machine learning. Interactive science, 2(67), 44-46.
19. Ilyshev, A.P. & Tolmachev, O.M. (2019). Artificial intelligence and neural network technologies in the digital platform for the breakthrough development of the Russian agro-industrial complex. Economy and society: modern models of development, 9(4(26)), 492-507.
20. Khudyakova, E., Nikanorov, M., Bystrenina, I., Cherevatova, T. & Sycheva, I. (2021). Forecasting the production of gross output in the agricultural sector of the Ryazan oblast. Estudios de Economía Aplicada, 39, 6. doi:10.25115/eea.v39i6.5171
21. Khudyakova, E.V., Nikanorov M.S. & Butyrin V.V. (2021). Problems of analysis and forecasting of the level of technical equipment of agricultural enterprises (on the example of the Ryazan region). Accounting in agriculture, 2, 69-77.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Рецензируемая статья посвящена актуальной проблеме прогнозирования налоговой нагрузки. Прогнозирование налоговой нагрузки хозяйствующих субъектов сегодня является недостаточно разработанной научной сферой, о чем отчасти свидетельствует состояние и динамика задолженности по налоговым платежам в консолидированный бюджет Российской Федерации. Исследование сущности налогового прогнозирования вызвано также необходимостью решения сложных задач по выводу России из кризисных условий, которые характеризуются экономической нестабильностью, экономическими санкциями и специальной военной операций. Кроме того, существует потребность в совершенствовании самой системы прогнозирования с целью повышения точности построенных прогнозов и учета наиболее весомых экономических факторов, в частности инвестиций. Новационный подход автора состоит в применении методов машинного обучения, которые практически не используются в научных исследованиях по налоговой тематике, ряд статей посвящен лишь теоретическому описанию возможностей применения данной группы методов. Кроме того, традиционно для прогнозирования нагрузки на микроуровне предприятия, как правило, используют динамические данные своей компании, представленный же подход основан на анализе совокупности данных хозяйствующих субъектов в сельском хозяйстве.
В качестве основных методов автор использует: деревья решений; случайный лес; градиентный бустинг; нейронные сети – в данном случае каждый из методов позволяет сопоставить его результаты с другим, выбрав тем самым наиболее точный вариант для прогнозирования. Преимущество статьи состоит также в достаточно большой по численности объектов выборке, которая прошла предварительную двухэтапную чистку и проверку(1 – на наличие выбросов, 2 – на наличие пропущенных значений). Работа с большим объемом данных (более 15000 организаций после обработки базы) позволила автору в существенной степени повысить качество модели и достоверность прогнозов.
Научная новизна состоит в разработке и апробации методического подхода к прогнозированию налоговой нагрузки хозяйствующего субъекта, основанного на применении методов машинного обучения и имеющего высокую статистическую устойчивость.
Стиль статьи научный, соответствует работам подобного уровня. Статья хорошо структурирована, она содержит следующие разделы: Введение, Литературный обзор, Материалы и методы исследования, Результаты исследования, Выводы и предложения. Это соответствует структуре IMRAD. Исследование грамотно выстроено, имеет внутреннюю логику и единство.
Библиография включает 20 позиций, в том числе научные статьи на отечественных и зарубежных исследований. Автор провел обзор научных мнений по вопросам применения различных методов прогнозирования. Апелляция к оппонентам не представлена, однако это логично, исходя из того, что «как показал проведенный обзор литературы, сфера применения методов машинного обучения в прогнозировании налоговой нагрузки не изучена».
Таким образом, представленная статья обладает элементами научной новизны, теоретической и практической значимости. Она представляет собой нестандартное трансдисциплинарное научное исследование, представляющее синтез финансовой и статистической наук, и будет интересна для читательской аудитории.
|
 Рус
Рус










