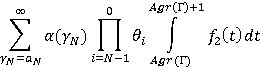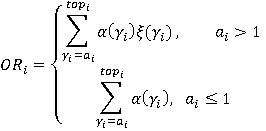|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Труб И.И., Труб Н.В.
Модель иерархических индексов баз данных с принятием решений и ее сравнение с минимаксной моделью
// Программные системы и вычислительные методы.
2018. № 1.
С. 18-36.
DOI: 10.7256/2454-0714.2018.1.25369 URL: https://nbpublish.com/library_read_article.php?id=25369
Модель иерархических индексов баз данных с принятием решений и ее сравнение с минимаксной моделью
Труб Илья Иосифович
кандидат технических наук
ведущий инженер-программист, ООО "Исследовательский центр Samsung"
127018, Россия, г. Москва, ул. Двинцев, 12, оф. C
Trub Ilya
PhD in Technical Science
Senior Software Engineer, Samsung Research Center Ltd.
127018, Russia, Moscow, ul. Dvintsev, 12, of. C

|
itrub@yandex.ru
|
|
 |
Другие публикации этого автора
|
|
|
Труб Наталья Васильевна
старший преподаватель, Московский государственный гуманитарно-экономический университет
107150, Россия, г. Москва, ул. Лосиноостровская, 49
Trub Nataliya
Senior Lecturer, Department of Mathematics, Moscow State University for the Humanities and Economics
107150, Russia, g. Moscow, ul. Losinoostrovskaya, 49
|
|
ntrub73@mail.ru
|
|
 |
|
DOI: 10.7256/2454-0714.2018.1.25369
Дата направления статьи в редакцию:
05-02-2018
Дата публикации:
21-03-2018
Аннотация:
Предметом исследования является предложенная автором концепция иерархических bitmap-индексов. Она заключается в том, что в целях повышения производительности обработки запросов по фильтру времени индексы поддерживаются не только для значений основной единицы времени, но и произвольных более крупных кратных единиц. Объектом исследования является построение вероятностной модели, позволяющей оценить эффективность принятия решения: какую побитовую операцию применить на очередном уровне иерархии при построении результирующей выборки - дизъюнкцию или исключающее ИЛИ. Автор уделяет основное внимание обоснованию валидности модели и сравнению результатов с построенной ранее минимаксной моделью, в которой принятие решения выполнялось по заранее установленному правилу и не зависело от текущего состояния системы. Методологией исследования являются теория вероятностей, методы многокритериальной оптимизации и вычислительный эксперимент, а также сопутствующие им методы интуитивной оценки правдоподобия результатов. Основные выводы проведенного исследования: построена и верифицирована аналитическая модель динамического выбора индексной операции; показано, что предложенная дисциплина выбора дает более высокую производительность в сравнении с минимаксной моделью и разработано программное обеспечение, позволяющее получить численную оценку этой разности; предложена модель оценки расходов на динамическое принятие решения и весовая функция, позволяющая при том или ином выборе весов оценить эффективность модели с принятием решений и сделать выбор в пользу одной из двух моделей.
Ключевые слова:
иерархические bitmap-индексы, случайный поток событий, экспоненциальное распределение, полная вероятность, дизъюнкция, исключающее ИЛИ, минимаксное правило, разбиение на группы, многокритериальная оптимизация, весовая функция
Abstract: The subject of the study is the concept of hierarchical bitmap-indexes proposed by the authors. In order to improve the processing performance of queries on the time filter, the indices are supported not only for the values of the basic unit of time, but also for arbitrary larger multiple units. The object of the study is to construct a probabilistic model that makes it possible to evaluate the effectiveness of decision making: what bitwise operation to apply at the next level of the hierarchy when constructing the resulting sample is a disjunction or an exclusive OR. The author focuses on justifying the validity of the model and comparing the results with the previously constructed minimax model, in which the decision was made according to a pre-established rule and did not depend on the current state of the system. The methodology of the study is probability theory, methods multicriteria optimization and computational experiment, as well as related methods of intuitive evaluation of the likelihood of the results. Main conclusions of the study: an analytical model of the dynamic selection of an index operation has been constructed and verified; It is shown that the proposed discipline of choice gives higher productivity in comparison with the minimax model and software is developed to obtain a numerical estimate of this difference; a model for estimating the costs of dynamic decision making and a weight function that allows one to evaluate the efficiency of the model with decision making and to choose one of the two models is proposed for this or that choice of weights.
Keywords: hierarchical bitmap-indexes, random flow of events, exponential distribution, total probability, disjunction, exclusive OR, minimax rule, binning, multi-criterial optimization, weighted function
Введение
Настоящая работа является продолжением [8], в которой была предложена концепция иерархических bitmap-индексов для ускорения обслуживания с их помощью поисковых запросов. Построенная модель учитывала тот факт, что в качестве аггрегирующей операции на очередном уровне иерархии может использоваться как дизъюнкция (логическое ИЛИ), так и сложение по модулю 2 (исключающее ИЛИ). Кратко напомним существо дела. Предположим для примера, что имеются построенные индексные битовые строки для каждого часа и для каждой минуты. Пусть требуется выбрать все записи с временнЫм свойством, для которого заведен индекс, лежащим в диапазоне от начала часа до некоторого значения t минут. Тогда, если t не превышает 30 (половины часа), применяется операция OR по битовым строкам, соответствующим значениям минутного индекса от 0 до t-1; в противном случае берется часовой индекс и с помощью операции XOR из него исключаются минутные индексы, соответствующие значениям минутного индекса от t до 59. Это правило минимизирует максимальное количество индексных операций, необходимых для вычисления результирующей выборки на текущем уровне иерархии. Согласно ему, выбор операции зависит только от параметров запроса на выборку данных и никак не учитывает наличие/отсутствие самих данных для интервалов слева и справа от t. Нетрудно видеть, что такая стратегия выбора операции не является единственно возможной. Можно подсчитать фактическое количество индексов в часовом интервале слева и справа от t и, вне зависимости от того меньше или больше t получаса, выбирать OR, если слева значений меньше, чем справа, и XOR – в противном случае. Это уменьшит количество операций, но и потребует дополнительных действий на подсчет фактического количества индексов в часе слева и справа от t. Поэтому моделирование иерархии индексов было бы неполным без исследования также и альтернативной – динамической – стратегии и численной оценки ее эффективности в сравнении с использованной в [8] статической. Построению и анализу модели для такой стратегии и посвящена данная работа.
Понятие иерархических bitmap-индексов (hierarchical bitmap indexes, встречается также multi-level bitmap indexes) было введено сравнительно недавно, поэтому терминология в этой области еще не является устоявшейся и общепринятой. Впервые оно появилось в работе [12], было развито в [16] и других работах тех же польских авторов. Но смысл в него вкладывался несколько иной: в этих работах авторы предложили концепцию индексирования свойств, являющихся множествами значений некоторых простых типов (set-valued attribute). Следующим шагом в этом направлении явилась вышедшая из той же научной школы работа [10], в которой было предложено использование иерархических bitmap-индексов для индексиования многомерных данных (dimensional data indexing). Тот смысл, в котором термин используется в [8] и настоящей работе, известен в англоязычной литературе также как binning - объединение отдельных значений данных в группы по некоторому правилу и создание укрупненных индексов по этим группам. Очень хороший обзор результатов по binning с подробным объяснением основных концепций на примерах содержится в [15]. Отмечено, что данная технология хорошо подходит для больших массивов результатов различных научных и технических измерений, таких как давление, температура и пр. Содержательными примерами использования binning являются более поздние работы [11],[17] и [18]. Наиболее близко к идеям, изложенным в настоящей статье, примыкают сравнительно недавние работы американских специалистов [13] и [14]. В них рассматривается задача выбора между OR- и XOR-операциями, которые названы inclusive query plan и exclusive query plan соответственно; сформулирована проблема оптимального выбора иерархии индексов (cut selection problem), предложены некоторые эвристические алгоритмы ее решения, применение которых проиллюстрировано на синтетических наборах данных.
В данной работе задача оценки эффективности использования иерархических bitmap-индексов решается с помощью формально обоснованной математической модели методами теории вероятностей и является первой работой подобного рода. В этой модели как содержимое базы данных, так и содержимое поисковых запросов, описываются аналитически с помощью известных вероятностных распределений, а показатели эффективности доводятся до вычисленных по выведенным формулам значений. Модель хорошо подходит для индексирования атрибута, явлющегося значением времени (примеры приложений с такими атрибутами приведены в [7]), но может быть доработана и продолжена для других типов атрибутов, таких как те же результаты измерений различных физических величин.
В первой части приведены основные обозначения и дается постановка задачи. Вторая часть содержит вывод уравнений и обоснование корректности построенной модели. В третьей части описаны различные способы расчета дополнительных расходов на динамическое принятие решения. Четвертая часть состоит из описания результатов расчетов, графиков и сравнительного анализа обеих моделей.
1. Постановка задачи
Напомним основные определения, введенные в [8]:
· 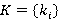 , i=1,..,N – множество натуральных чисел больше единицы, задающее иерархию индексов, где , i=1,..,N – множество натуральных чисел больше единицы, задающее иерархию индексов, где 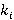 есть кратность i-го индекса по отношению к предыдущему, а есть кратность i-го индекса по отношению к предыдущему, а 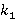 есть размер первого индекса в основной неделимой единице времени, например, в секундах; есть размер первого индекса в основной неделимой единице времени, например, в секундах;
· 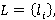 i=0,…,N, где i=0,…,N, где  - множество фактических размеров индексов в основной единице времени; - множество фактических размеров индексов в основной единице времени;
· элементарное граничное условие (ЭГУ) – ограничение на интервал времени – фильтр запроса. Заключается в том, что левая граница интервала должна совпадать с границей самого крупного индекса иерархии (он имеет номер N). Требуется для построения аналитической модели, т.к. обеспечивает единственность разложения интервала времени по размерам индексов.
· B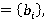 i=0,1,..,N, - множество коэффициентов разложения интервала времени T, удовлетворяющего ЭГУ, по размерам индексов в виде i=0,1,..,N, - множество коэффициентов разложения интервала времени T, удовлетворяющего ЭГУ, по размерам индексов в виде 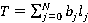 ; ;
· 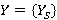 , S=0,1,2,… - дискретная плотность распределения случайной величины Y или вероятность того, что поисковый запрос на выборку данных потребует использования ровно S индексов; , S=0,1,2,… - дискретная плотность распределения случайной величины Y или вероятность того, что поисковый запрос на выборку данных потребует использования ровно S индексов;
· 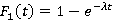 – функция распределения длины интервала времени между последовательными записями в базу данных. Вероятностная модель может быть построена только для экспоненциального распределения, так как требует выполнения свойства отсутствия последействия, которым обладает только оно [1,2]; – функция распределения длины интервала времени между последовательными записями в базу данных. Вероятностная модель может быть построена только для экспоненциального распределения, так как требует выполнения свойства отсутствия последействия, которым обладает только оно [1,2];
· 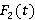 – функция распределения длины интервала времени, по которому делается запрос на выборку данных. Может быть произвольной. – функция распределения длины интервала времени, по которому делается запрос на выборку данных. Может быть произвольной.
K, 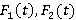 – являются входными данными для задачи, – являются входными данными для задачи, 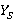 – результатом, который нужно получить. – результатом, который нужно получить.
Выбор между OR и XOR на i-ом уровне иерархии для всех i от 0 до N-1 делался следующим образом. Если значение 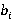 не превышает половины от не превышает половины от 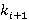 , выбиралась OR, в противном случае выбиралась XOR. Нетрудно видеть, что такой выбор реализует хорошо известный в исследовании операций и методах принятия решений принцип минимакса [3,6,9]. В самом деле, возьмем, как обычно, для примера минутные и часовые индексы. Если в разложении длины интервала запроса количество минут равно 15, то выполнив OR по всем индексам от 0 до 14, мы в наихудшем случае получим 15 битовых строк, а для XOR – 46 (45 строк от 15 до 59 плюс строка для часового индекса). Если же количество минут равно 45, то для XOR наихудшим значением будет 16, а для OR – 45. При этом никак не учитывается фактическое количество заполненных индексов слева и справа от запрашиваемого количества минут в пределах данного часа. , выбиралась OR, в противном случае выбиралась XOR. Нетрудно видеть, что такой выбор реализует хорошо известный в исследовании операций и методах принятия решений принцип минимакса [3,6,9]. В самом деле, возьмем, как обычно, для примера минутные и часовые индексы. Если в разложении длины интервала запроса количество минут равно 15, то выполнив OR по всем индексам от 0 до 14, мы в наихудшем случае получим 15 битовых строк, а для XOR – 46 (45 строк от 15 до 59 плюс строка для часового индекса). Если же количество минут равно 45, то для XOR наихудшим значением будет 16, а для OR – 45. При этом никак не учитывается фактическое количество заполненных индексов слева и справа от запрашиваемого количества минут в пределах данного часа.
Наихудший случай не означает «обязательно реализуемый». Реализуется он только в том случае, когда для каждой минуты часа в БД имеется хотя бы одна запись, т.е. для каждой минуты существует заполненный индекс. Но ведь при не слишком высокой интенсивности занесения данных в БД (т.е. при малых значениях λ) вполне может оказаться и так, что в первые 15 минут часа в БД было занесено больше значений, чем в последующие 45 или в последние 15 минут больше значений, чем в 45 предыдущих. И тогда минимаксный выбор операции даст худший по производительности вариант. Поэтому динамическая стратегия выбора операции, основанная на знании фактического количества индексов, окажется лучше принципа минимакса. Но это улучшение не является бесплатным – для его реализации нужно выполнить дополнительную работу по вычислению количества индексов. Поэтому представляют интерес следующие вопросы: насколько серьезное улучшение значения 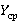 дает динамическая стратегия в сравнении с принципом минимакса и как его измерить? насколько соотносятся с этим улучшением указанные выше дополнительные расходы? стОит ли улучшение того, чтобы на эти расходы пойти? Предложенная далее альтернативная [8] модель позволяет с той или иной степенью детализации дать на эти вопросы ответ. дает динамическая стратегия в сравнении с принципом минимакса и как его измерить? насколько соотносятся с этим улучшением указанные выше дополнительные расходы? стОит ли улучшение того, чтобы на эти расходы пойти? Предложенная далее альтернативная [8] модель позволяет с той или иной степенью детализации дать на эти вопросы ответ.
2. Вероятностная модель
Модель строится на основе тех же принципиальных понятий, что и для правила минимакса. Различия в логике принятия решения находят отражение лишь в окончательных расчетных формулах. Далее они будут акцентированы. Основных понятий, лежащих в основе модели, два – это K-разложение и носитель K-разложения. Напомним их определения.
Определение 1. Множество 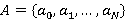 называется K-разложением числа S, если оно удовлетворяет совокупности следующих условий: называется K-разложением числа S, если оно удовлетворяет совокупности следующих условий:
· 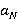 – произвольное неотрицательное целое число; – произвольное неотрицательное целое число;
·  , i=0,..,N-1, где ceil(x) означает округление в большую сторону в случае нецелого аргумента; , i=0,..,N-1, где ceil(x) означает округление в большую сторону в случае нецелого аргумента;
· 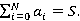
Смысл этого понятия заключается в том, что оно позволяет провести декомпозицию задачи вычисления вероятности на составляющие, соответствующие каждому из K-разложений. Если обозначить 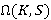 всё множество K-разложений S, искомую вероятность можно выразить как всё множество K-разложений S, искомую вероятность можно выразить как
|
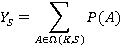
|
(1)
|
Таким образом, задача вычисления вероятности сводится к вычислению вероятности P(A) каждого K-разложения числа S. Решение же задачи генерации множества K-разложений подробно рассмотрено в [8].
Определение 2. Множество 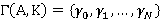 называется носителем разложения A в иерархии K, если его элементы удовлетворяют следующим условиям: называется носителем разложения A в иерархии K, если его элементы удовлетворяют следующим условиям:
1) 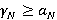 ; ;
2) 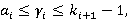 i=0,..,N-1, i=0,..,N-1, 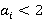 ; ;
3) 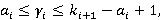 i=0,..,N-1, i=0,..,N-1, 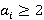 . .
Понятие носителя позволяет ответить на вопрос: каково должно быть разложение
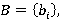 i=0,1,..,N интервала фильтра запроса для того, чтобы при вычислении результатов запроса вероятность получения именно разложения A была ненулевой, т.е. чтобы событие A было возможным. Ответ заключается в том, что оно должно быть частью носителя. i=0,1,..,N интервала фильтра запроса для того, чтобы при вычислении результатов запроса вероятность получения именно разложения A была ненулевой, т.е. чтобы событие A было возможным. Ответ заключается в том, что оно должно быть частью носителя.
Перед тем как представить формулу для P(A), дадим точную формулировку правила, согласно которому на каждом уровне иерархии выбирается операция. Пусть i-ый коэффициент разложения интервала фильтра запроса T равен 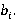 Пусть также Пусть также 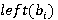 есть количество индексов для интервалов i-го уровня, начало которых лежат в диапазоне есть количество индексов для интервалов i-го уровня, начало которых лежат в диапазоне 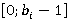 , а , а 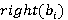 есть количество индексов для интервалов i-го уровня, начало которых лежат в диапазоне есть количество индексов для интервалов i-го уровня, начало которых лежат в диапазоне 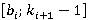 , увеличенное на единицу (т.к. для операции XOR следует считать еще и один индекс следующего уровня). Тогда при выполнении условия , увеличенное на единицу (т.к. для операции XOR следует считать еще и один индекс следующего уровня). Тогда при выполнении условия
|
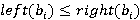
|
(2)
|
выбирается операция OR, в противном случае выбирается операция XOR. Таким образом, при равенстве приоритет будем отдавать операции OR.
Вывод формулы P(A) основывается на свойстве отсутствия последействия у экспоненциального распределения, а, следовательно, независимости наступления событий на двух непересекающихся интервалах и возможности применения в этом случае биномиального распределения для вычисления вероятности наступления события ровно в m случаях из n [1].
|
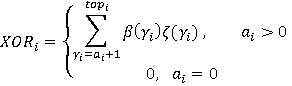
|
(6)
|
|
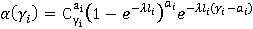
|
(7)
|
|
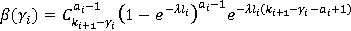
|
(8)
|
|
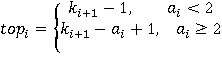
|
(9)
|
|
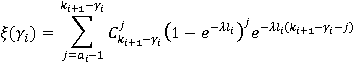
|
(10)
|
|
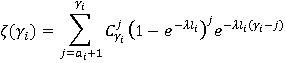
|
(11)
|
|
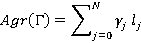
|
(12)
|
Разберем вероятностную аргументацию формулы (3), сделав отдельный акцент на тех ее элементах, на которые влияет правило (2). В первую очередь, мультипликативный характер (3) объясняется независимостью расчета вероятностей для каждого элемента K-разложения ввиду экспоненциальности 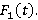 Величину Величину 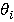 можно рассматривать как вероятность того, что i-я компонента множества A примет значение можно рассматривать как вероятность того, что i-я компонента множества A примет значение 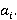 Это может произойти в двух случаях: при применении операции OR или XOR, что выражается формулой (4), а вероятности применения каждой из них обозначены соответственно Это может произойти в двух случаях: при применении операции OR или XOR, что выражается формулой (4), а вероятности применения каждой из них обозначены соответственно 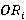 и и 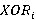 . Остановимся теперь подробнее на формуле (5). Смысл выражения . Остановимся теперь подробнее на формуле (5). Смысл выражения 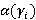 очевиден – это вероятность того, что из очевиден – это вероятность того, что из 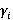 интервалов i-го уровня индексы существуют только для интервалов i-го уровня индексы существуют только для 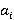 из них. Это выражение присутствует и в минимаксной модели. Два отличия, обсуловленные применением правила (2), заключаются в верней границе для и наличии дополнительного множителя из них. Это выражение присутствует и в минимаксной модели. Два отличия, обсуловленные применением правила (2), заключаются в верней границе для и наличии дополнительного множителя 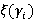 . В минимаксной модели верхняя граница не могла превысить половины от кратности i-го индекса - значения , т.к. операция OR применялась только в этом случае. Теперь же она может быть применена и при нахождении в правой половине диапазона. Но при условии, что справа от . В минимаксной модели верхняя граница не могла превысить половины от кратности i-го индекса - значения , т.к. операция OR применялась только в этом случае. Теперь же она может быть применена и при нахождении в правой половине диапазона. Но при условии, что справа от 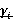 индексов будет не меньше, чем слева. А это условие как раз и задается выражением (10). Наименьшее значение для количества индексов справа равно индексов будет не меньше, чем слева. А это условие как раз и задается выражением (10). Наименьшее значение для количества индексов справа равно 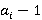 , т.к. с учетом присутствия одного более крупного индекса в XOR общее число индексов как раз будет равно , что согласно (2) приводит к выбору OR в случае равенства. Если же равно 0 или 1, то согласно (2) не имеет никакого значения, что находится справа, т.к. при наступлении события, выражаемого (7), всегда будет выбрана OR. По этой же причине слагаемое при , т.к. с учетом присутствия одного более крупного индекса в XOR общее число индексов как раз будет равно , что согласно (2) приводит к выбору OR в случае равенства. Если же равно 0 или 1, то согласно (2) не имеет никакого значения, что находится справа, т.к. при наступлении события, выражаемого (7), всегда будет выбрана OR. По этой же причине слагаемое при 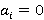 отсутствует вовсе, т.к. для этого значения в принципе невозможен выбор XOR. Для формулы (6) аргументация аналогична. Поясним лишь выбор нижних значений индекса суммирования в (6) и (11), т.к. он отличается от (5) и (10). Согласно (2), для того, чтобы выла выбрана XOR, не может принять значение , т.к. в этом случае слева окажется не более индексов, и будет выбрана OR. Нижнее значение в (11) опять-таки объясняется той же причиной – для выбора XOR слева от не может находиться и менее индексов. отсутствует вовсе, т.к. для этого значения в принципе невозможен выбор XOR. Для формулы (6) аргументация аналогична. Поясним лишь выбор нижних значений индекса суммирования в (6) и (11), т.к. он отличается от (5) и (10). Согласно (2), для того, чтобы выла выбрана XOR, не может принять значение , т.к. в этом случае слева окажется не более индексов, и будет выбрана OR. Нижнее значение в (11) опять-таки объясняется той же причиной – для выбора XOR слева от не может находиться и менее индексов.
Теперь разберем смысл выражения (12) и интеграла, входящего в (3), т.к. именно в нем учитывается такая составляющая задачи как функция 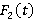 . Заметим, что из формул (4), (5) и (6) следует, что (3) после раскрытия скобок представляет собой сумму некоторого количества произведений, каждому из которых соответствует свое множество-носитель . Заметим, что из формул (4), (5) и (6) следует, что (3) после раскрытия скобок представляет собой сумму некоторого количества произведений, каждому из которых соответствует свое множество-носитель 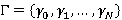 , предопределенный выбором значения в i-ой сумме. Этому носителю соответствует фильтр запроса, лежащий в единичном интервале с левой границей, заданной формулой (12). Поэтому каждое такое произведение нужно в итоге домножить на интеграл от плотности распределения длины фильтра запроса, в котором пределы интегрирования соответствуют множеству-носителю этого произведения. Ниже приведен фрагмент кода на языке C, демонстрирующий принципиальные алгоритмические особенности реализации этой схемы вычислений с помощью рекурсии. , предопределенный выбором значения в i-ой сумме. Этому носителю соответствует фильтр запроса, лежащий в единичном интервале с левой границей, заданной формулой (12). Поэтому каждое такое произведение нужно в итоге домножить на интеграл от плотности распределения длины фильтра запроса, в котором пределы интегрирования соответствуют множеству-носителю этого произведения. Ниже приведен фрагмент кода на языке C, демонстрирующий принципиальные алгоритмические особенности реализации этой схемы вычислений с помощью рекурсии.
/*рекурсивная функция, вычисляющая сумму (3).
Аргументы:
prod – накопленная цепочка произведения слагаемых из сумм (5) и (6), каждый элемент цепочки соответствует очередному значению i и некоторому для него;
level – значение текущего уровня иерархии, т.е. значение i;
agr – текущее накопленное значение в сумме (12). В конце рекурсии при i=0 в этом параметре накопится нижний предел интегрирования для (3)
*/
/* Глобальные переменные:
NN – количество уровней иерархии N
masK – множество Kкратностей индексов
masL – множество Lдлин индексов
masA – множество A (текущее K-разложение, для которого вычисляется вероятность)
Sum – текущая накопленная внешняя сумма при вычислении (3). После завершения вычислений в ней будет итоговое значение
liam – параметр экспоненциального распределения 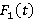
eps – точность сходимости внешней суммы в (3)
*/
/*Первый вызов выполняется так: mainRec(1.0,NN,0);*/
void mainRec(double prod, int level, int agr)
{
int i, j, bottom, top, bottom1, top1;
double sumOld, value,x,cond,sum1,value1;
if ((level != NN) && (level != 0)) {
/*вычисление границ суммирования в (5) */
bottom=masA[level];
if (masA[level]<2) top=masK[level]-1;
else top=masK[level]-masA[level]+1;
x=exp(-liam*masL[level-1]);
/*реализация (5)*/
for (i=bottom; i<=top;i++) {
value=comb(masA[level],i,x); /*вычисление по формуле (7)*/
if (masA[level]>1) {
/*вычисления по формуле (10)*/
sum1=0.0;
bottom1=masA[level]-1;
top1=masK[level]-i;
for(j=bottom1;j<=top1;j++) {
sum1=sum1+comb(j,masK[level]-i,x);
}
value=value*sum1;
}
/*вычисление на уровне level в (5) выполнено, делаем рекурсивный вызов, продолжая увеличивать длину цепочки*/
mainRec(prod*value,level-1,agr+i*masL[level-1]);
}
/*выполняем вычисления по формуле (6)*/
if (masA[level]>0) {
for (i=bottom+1;i<=top;i++) {
value=comb(masA[level]-1,masK[level]-i,x); /*формула (8)*/
sum1=0.0;
bottom1=masA[level]+1;
top1=i;
/*формула (11)*/
for(j=niz1;j<=verh1;j++) {
sum1=sum1+comb(j,i,x);
}
value=value*sum1;
/*вычисление на уровне level для (6) выполнено, делаем рекурсивный вызов*/
mainRec(prod*value,level-1,agr+i*masL[level-1]);
}
}
}
/*здесь всё то же самое, только в конце домножаем на интеграл и рекурсивный вызов не делаем*/
else if (level==0) {
bottom=masA[0];
if (masA[0]<2) top=masK[0]-1;
else top=masK[0]-masA[0]+1;
x=exp(-liam);
for (i=bottom;i<=top;i++) {
value=comb(masA[level],i,x);
if (masA[0]>1) {
sum1=0.0;
bottom1=masA[0]-1;
top1=masK[0]-i;
for(j=bottom1;j<=top1;j++) {
sum1=sum1+comb(j,masK[0]-i,x);
}
value=value*sum1;
}
value1=0.0;
if ((i>bottom) && (masA[0]>0)) {
value1=comb(masA[0]-1,masK[0]-i,x);
sum1=0.0;
bottom1=masA[0]+1;
top1=i;
for(j=bottom1;j<=top1;j++) {
sum1=sum1+comb(j,i,x);
}
value1=value1*sum1;
}
value=value+value1;
/*наращиваемитоговуюсумму*/
Sum=Sum+prod*value*integral(agr+i);
}
}
else { /*level = N*/
i=masA[NN];
sumOld=0.0;
x=exp(-liam*masL[NN-1]);
/*суммируем ряд (3) до достижения требуемой точности сходимости*/
while(1) {
value=comb(masA[NN],i,x);
mainRec(value,NN-1,i*masL[NN-1]);
if (fabs(Sum-sumOld) <= eps) break;
i=i+1;
sumOld = Sum;
}
}
}
}
Построив такую достаточную сложную модель, со множеством логических нюансов, нельзя не задаться вопросом, насколько можно ей доверять, не закралась ли где-нибудь логическая ошибка? Способ верификации достаточно прост – сумма вероятностей , вычисленных по формуле (1) по S от нуля до бесконечности, должна сходиться к единице, т.к. образует полную группу событий. Разумеется, экспериментальная проверка подтвердила эту сходимость (иначе данная работа просто не была бы написана), но следует найти и какое-то аналитическое подтверждение, свидетельствующее о том, что в постановке задачи и вероятностных рассуждениях в самом деле не была допущена ошибка. Приведем простейший пример, для которого значения , выписанные строго в соответствии с правилом (2) и формулой (3), можно просуммировать вручную в аналитической форме.
Рассмотрим задачу, в которой N=1, K={4}, причем длина интервала запроса ограничена сверху значением крупного индекса, т.е. не может превышать значения 4. Тогда для корректности постановки задачи следует потребовать выполнения условия:
|
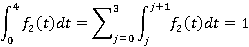
|
(13)
|
S в этой задаче может принимать три возможных значения – 0, 1 или 2. Схема доказательства будет следующей. Сумму 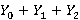 можно путем соответствующей группировки слагаемых представить в следующем виде: можно путем соответствующей группировки слагаемых представить в следующем виде:
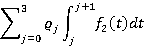
Если удастся показать, что для каждого j=0,..,3 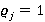 , то с учетом (13) корректность модели будет подтверждена. Для краткости пусть , то с учетом (13) корректность модели будет подтверждена. Для краткости пусть 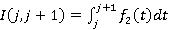 . Итак, . Итак,
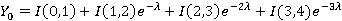
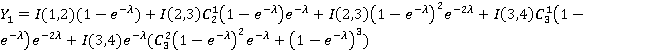
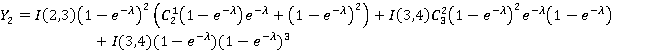
Прокомментируем выборочно на соответствие (2), например, два последних слагаемых второй формулы. Предпоследнее слагаемое вычисляет вероятность применения операции OR, а именно: из первых трех единичных интервалов проиндексирован ровно один, что в четвертом – не имеет при этом значения, т.к. для XOR потребуется по крайней мере один индекс – для полной четверки интервалов, а в случае равенства приоритет имеет OR. Последнее слагаемое вычисляет вероятность применения операции XOR: последний интервал не проиндексирован, из первых трех проиндексированы 2 или 3. Так же можно убедиться в справедливости всех уравнений в целом. Раскрыв скобки и просуммировав слагаемые по отдельности для каждого I из всех уравнений, убедимся что все четыре суммы равны единице. Нет необходимости приводить здесь эти элементарные выкладки, т.к. заинтересованный читатель легко может проверить их самостоятельно.
3. Дополнительные расходы
Как уже было отмечено, исследуемая в работе дисциплина выбора операции требует для своего применения наличия дополнительной информации – знания количества индексов на текущем уровне иерархии i слева и справа от в пределах интервала времени, соответствующего уровню i+1. Разумеется, дополнительные расходы на сбор такой информации являются платой за это знание. Оценим их. В качестве меры этой оценки примем случайную величину Z – общее количество индексов, которые придется суммарно сосчитать на всех уровнях иерархии для применения правила (2). При этом возникает вопрос: по какому алгоритму их на каждом уровне иерархии подсчитывать? Можно предложить разные алгоритмы такого подсчета, например:
· Простой. Перебор всех интервалов i-го уровня в пределах интервала (i+1)-го уровня и подсчет существующих индексов слева и справа.
· Прямой урезанный. Сначала считаем слева – от 0 до (пусть там m индексов), затем считаем справа, и если доходим до значения m-1, прекращаем подсчет – выбирается OR.
· Обратный урезанный. Сначала считаем справа – от (пусть там m индексов), затем считаем слева от нуля, и если достигли значения m+2, не дойдя до , прекращаем подсчет – выбирается XOR.
· Случайный урезанный. С вероятностью 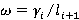 считаем сначала справа, с вероятностью 1-ω слева. При таком выборе мы будем с большей вероятностью начинать с меньшего интервала, причем вероятность естественным образом зависит от расположения . Является комбинацией двух предыдущих алгоритмов. считаем сначала справа, с вероятностью 1-ω слева. При таком выборе мы будем с большей вероятностью начинать с меньшего интервала, причем вероятность естественным образом зависит от расположения . Является комбинацией двух предыдущих алгоритмов.
· Детерминировнный урезанный. То же, что и предыдущий, но начинаем всегда с того интервала, который имеет меньшую длину, т.е. если меньше середины, сначала считаем слева, если больше, то справа.
Для оценки величины 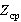 для каждого из алгоритмов можно построить свою вероятностную модель, но это будет малополезным с практической точки зрения углублением и может служить лишь хорошим упражнением в освоении теории вероятностей. Понятно, что численные результаты существенно отличаться не будут. Поэтому для простоты и ясности изложения остановимся на наименее экономичном, но наиболее ясном первом алгоритме. Так как случайная величина Z не зависит от функции для каждого из алгоритмов можно построить свою вероятностную модель, но это будет малополезным с практической точки зрения углублением и может служить лишь хорошим упражнением в освоении теории вероятностей. Понятно, что численные результаты существенно отличаться не будут. Поэтому для простоты и ясности изложения остановимся на наименее экономичном, но наиболее ясном первом алгоритме. Так как случайная величина Z не зависит от функции 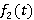 , для вычисления ее распределения нет необходимости раскладывать S на слагаемые. В случае экспоненциального , для вычисления ее распределения нет необходимости раскладывать S на слагаемые. В случае экспоненциального 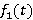 формула для среднего значения записывается сразу: формула для среднего значения записывается сразу:
|
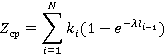
|
(14)
|
В (14) выражение в скобках есть в терминах биномиального распределения вероятность успеха при одном испытании, – количество испытаний.
Итак, важно отметить, что если в минимаксной модели эффективность оценивалась только по значению , то для динамической модели целевой функцией для сравнения с минимаксной моделью будет
|
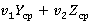
|
(15)
|
где 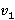 и и 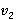 – некоторые весовые коэффициенты, учитывающие важность критериев Y и Z. Выбор этих коэффициентов является во многом субъективным, зависит от технической конкретики задачи (например, соотношения расхода времени на одну дизъюнкцию битовой строки и один инкремента счетчика индексов) и остается на усмотрение вычислителя, который использует модель для принятия того или иного проектного решения. Понятия взвешенной функции и важности критериев и их использование в задачах оптимизации являются широко распространенными и изучались, например, в работах известного отечественного специалиста [4,5]. – некоторые весовые коэффициенты, учитывающие важность критериев Y и Z. Выбор этих коэффициентов является во многом субъективным, зависит от технической конкретики задачи (например, соотношения расхода времени на одну дизъюнкцию битовой строки и один инкремента счетчика индексов) и остается на усмотрение вычислителя, который использует модель для принятия того или иного проектного решения. Понятия взвешенной функции и важности критериев и их использование в задачах оптимизации являются широко распространенными и изучались, например, в работах известного отечественного специалиста [4,5].
4. Численные результаты
Вычисления велись для экспоненциальных распределений 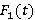 и c и c 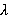 =1/30 и =1/30 и 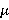 =0.001. Это соответствует появлению новой записи в БД примерно каждые 30 секунд и средней длине фильтра запроса 17 минут, т.е. ищутся все записи, занесенные в БД за период 17 минут. Сходимость внешнего ряда в (3) фиксировалась по достижении точности =0.001. Это соответствует появлению новой записи в БД примерно каждые 30 секунд и средней длине фильтра запроса 17 минут, т.е. ищутся все записи, занесенные в БД за период 17 минут. Сходимость внешнего ряда в (3) фиксировалась по достижении точности 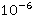 . Для каждого эксперимента проверялось выполнения условия . Для каждого эксперимента проверялось выполнения условия 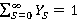 до достижения значения до достижения значения 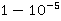 . .
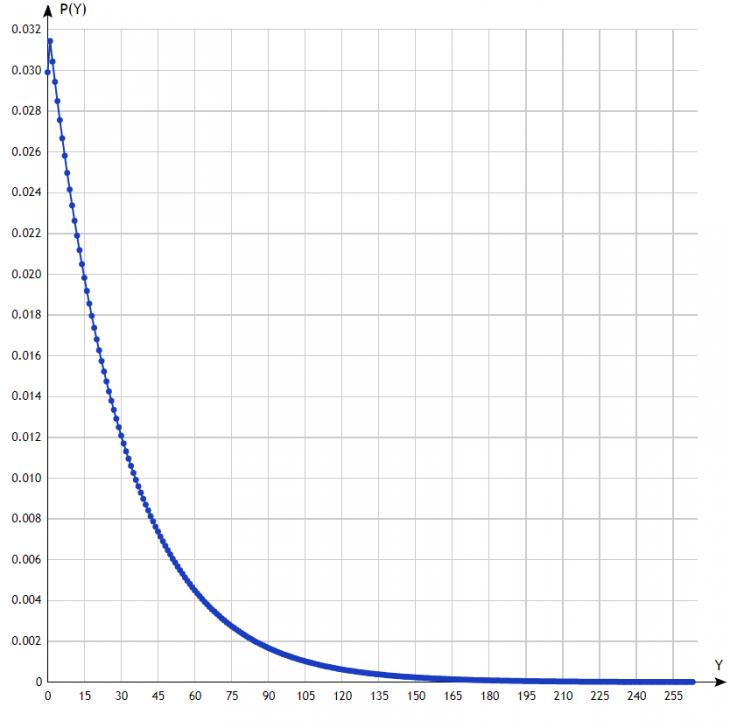
Рис. 1. N=1, K={6}
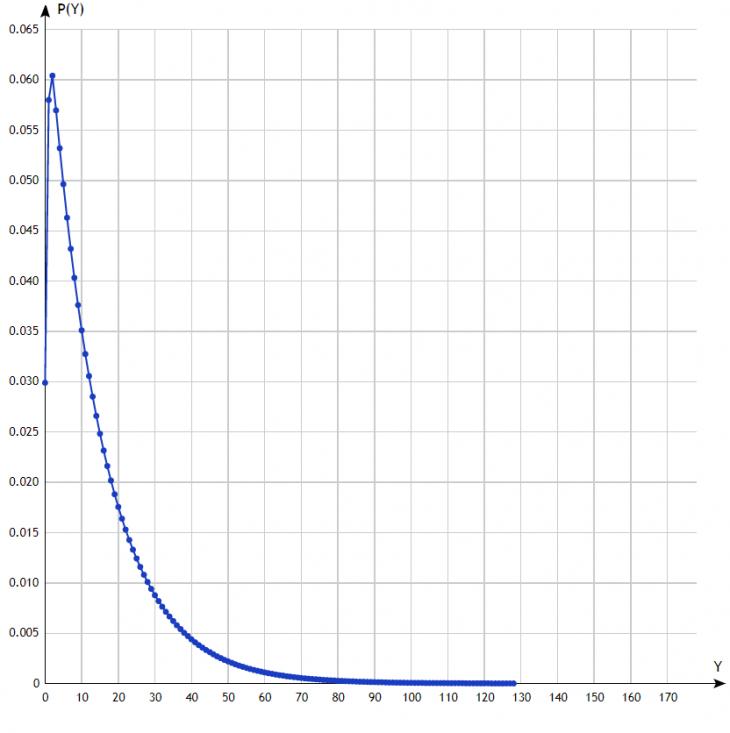
Рис.2. N=1, K={60}
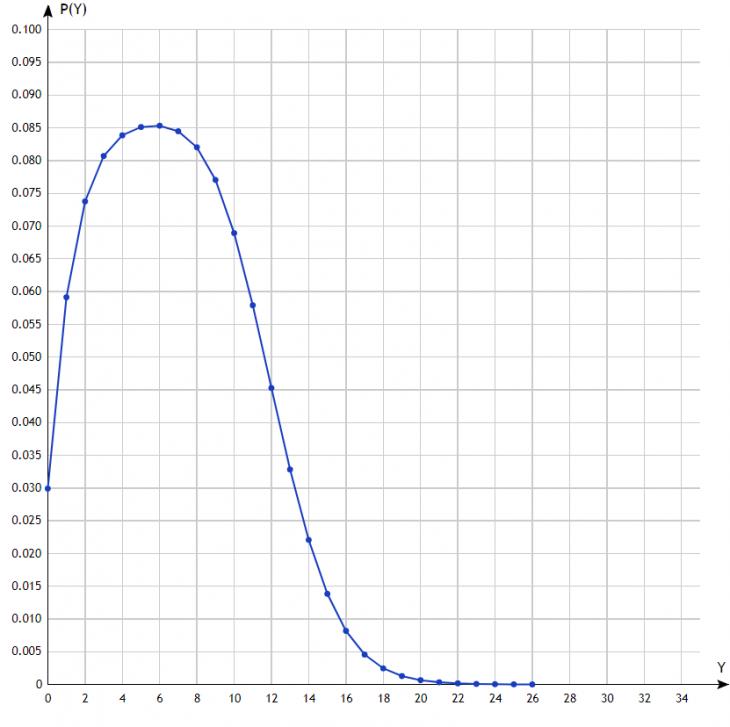
Рис.3. N=1, K={600}.
На рис.1,2,3 изображены распределения случайной величины для размера иерархии N=1, K={6}, {60} и {600}. Объяснение поведения этих зависимостей принципиально не отличаются от объяснений аналогичных зависимостей для минимаксной стратегии, данных в [8].
Но наибольший интерес представляет рис.4, где приведены зависимости от k для N=1, K={k} для минимаксной (тонкая линия) и динамической стратегии (линия потолще) при прочих равных условиях.
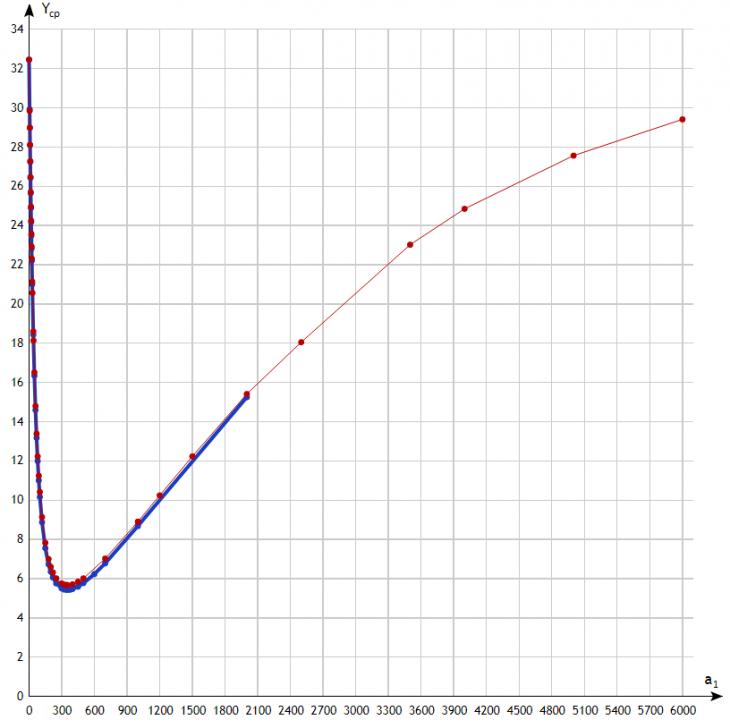
Рис.4. N=1.
Мы видим, что для динамической стратегии действительно меньше, чем для минимаксной, но ненамного. В целом же, несмотря на существенные различия в семантике модели, зависимости ведут себя примерно одинаково. Оптимальное значение достигается в обоих случаях приблизительно в точке 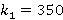 и для минимаксной стратегии равно 5.67, для динамической – 5.42. Сделаем еще два существенных комментария к этому рисунку: и для минимаксной стратегии равно 5.67, для динамической – 5.42. Сделаем еще два существенных комментария к этому рисунку:
· разница между для обеих стратегий ожидаемо должна возрастать при уменьшении λ, т.е. при уменьшении заполненности базы данных. В самом деле, представим себе пиковый случай, когда при высокой интенсивности занесения записей все или почти все единицы времени являются индексами. В этом случае разница между стратегиями исчезает. При снижении же нагрузки возрастает вероятность того, что в менее длинном интервале окажется больше индексов, чем более длинном. Эксперимент, проведенный для λ=1/60 это предположение подтвердил. Таким образом, использование динамической стратегии тем более оправдано, чем менее заполнена база данных;
· численная реализация динамической стратегии является с вычислительной точки зрения более сложной задачей, чем минимаксной. Трудность связана с наличием в модели дополнительных хвостовых сумм (10) и (11), которых в минимаксной модели нет. С ростом вычислять эти суммы становится всё труднее. Этим объясняется тот факт, что нижний график на рис.4 обрывается раньше, чем верхний, но на понимание того, как дальше ведет себя эта кривая, данный факт не влияет.
Наконец, на рис.5 приведен график зависимости 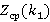 , построенный с помощью формулы (14) для N=2, K={ , построенный с помощью формулы (14) для N=2, K={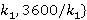 , т.е. индекс второй иерархии всегда равен одному часу. , т.е. индекс второй иерархии всегда равен одному часу.
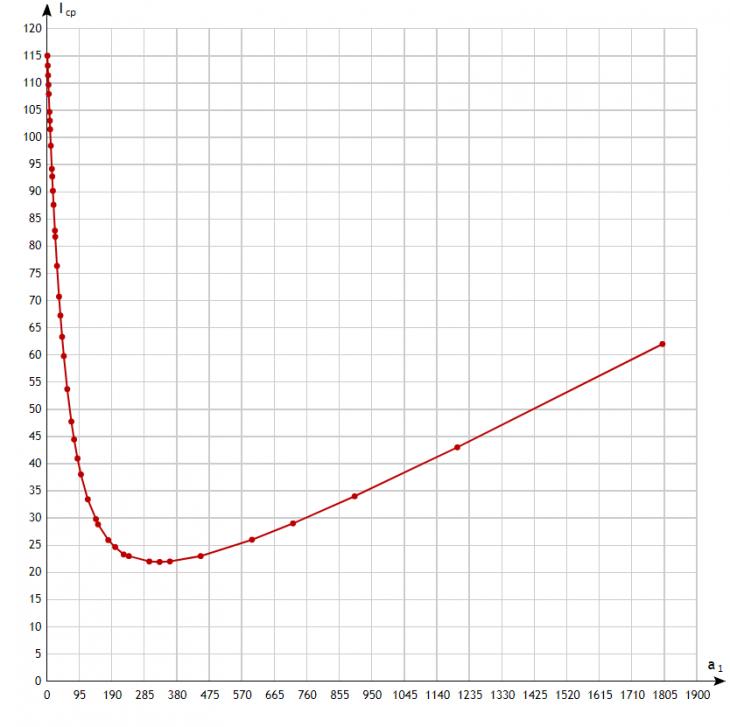
Рис. 5. N=2.
Для N=1 такая зависимость не представляет интереса, т.к. и без вычислений понятно, что это будет простая линейная зависимость. При N=2 получаем кривую с минимумом, достигаемым приблизительно при том же значении 350 и равным 21.9. Это означает, что при оптимальном выборе размера индекса для выполнения одного запроса придется в среднем подсчитать наличие 22 индексов, из них в операции в качестве битовых строк будут задействованы 5-6 из них.
Заключение
Модели, построенные в [8] и настоящей работе, по-видимому, подводят нас к границе того, что можно каким-то образом рассчитать по формулам для оценки эффективности применения иерархических индексов. Дальнейший отказ от каких-либо использованных ограничений делает аналитическую модель либо невозможной, либо практически бесполезной ввиду чрезвычайной сложности. Но это не означает, что все задачи аналитического моделирования решены, и вопросов не осталось, поскольку в указанных работах сделаны только первые шаги в части исследования результатов, которые можно получить с помощью построенных моделей. Было сделано слишком мало численных экспериментов, и они в большей степени преследовали цель подтвердить валидность модели, а не вывести какие-либо устойчивые свойства результирующих распределений. Поставить можно следующие задачи:
1) можно ли и с какой точностью приблизить распределение для случайной величины Y каким-либо известным распределением хотя бы для N=1? Какова зависимость между параметрами этого распределения и значениями λ и µ?
2) каков характер зависимости P(Y) от N и множества кратностей K? Ясно, что такую задачу следует в первую очередь корректно поставить, так как сразу неясно, как варьировать элементами множества K и какая именно зависимость исследуется;
3) те же вопросы можно поставить не только для экспоненциального , но и для других распределений.
4) как меняется сравнительная эффективность динамической модели по отношению к минимаксной при изменении параметров исходных распределений и значения N без учета дополнительных расходов? Если же их учитывать, при каких значениях весовых коэффициентов эта эффективность вообще имеет место?
Список вопросов можно продолжать и дальше, но достаточно трудно сказать, какой из них может в первую очередь представлять инженерный интерес при реализации концепции иерархических индексов на практике. С практической точки зрения может быть полезна и такая задача как снижение трудоемкости расчетов путем замены на приближенные выражения хвостов биномиальных распределений в (11) и (12), т.к. уже для N=2 расчеты могут быть проведены только при наличии достаточно мощного вычислительного ресурса.
Библиография
1. Вентцель Е.С. Теория вероятностей.-М.: Наука, 1969.-576 с.
2. Клейнрок Л. Теория массового обслуживания.-М.: Машиностроение, 1979.-432 с.
3. Ларичев О. Теория и методы принятия решений.-М.: Логос,2002.-392 с.
4. Подиновский В.В. Введение в теорию важности критериев в многокритериальных задачах принятия решений.-М.: Физматлит, 2007.-63 с.
5. Подиновский В.В., Потапов М.А. Метод взвешенной суммы критериев в анализе многокритериальных решений: PRO et CONTRA.-Бизнес-Информатика, № 3(25), 2013.-с.41-48.
6. Соколов А.В., Токарев В.В. Методы оптимальных решений. Т.1.-М.: Физматлит, 2011.-564 с.
7. Труб И.И. Аналитическая вероятностная модель bitmap-индексов. //Программные системы и вычислительные методы.-2016.-№4.-с.315-323. DOI: 10.7256/2305-6061.2016.4.21091
8. Труб И.И. Вероятностная модель иерархических индексов баз данных. //Программные системы и вычислительные методы.-2017.-№ 4.-с.15-31. DOI: 10.7256/2454-0714.2017.4.24437 URL: http://nbpublish.com/library_read_article.php?id=24437
9. Федоров В.В. Численные методы максимина.-М.: Наука, 1979.-280 с.
10. Chmiel J., Morzy T., Wrembel R. HOBI: Hierarchically Organized Bitmap Index for Indexing Dimensional Data. - In Proc. of the Eleventh International Conference on Data Warehousing and Knowledge Discovery (DaWaK), August, 2009, pp. 87-98. DOI: 10.1007/978-3-642-03730-6_8
11. Kim J.W. Binning Strategy for Hierarchical Bitmap Indices with Large Scale Domain Hierarchy. - International Journal of Applied Engineering Research, Volume 11, Number 18 (2016), pp.9289-9296.
12. Morzy M., Morzy T., Nanopoulos A., Manolopoulos Y. Hierarchical Bitmap Index: an Efficient and Scalable Indexing Technique for Set-Valued Attributes. - In Proc. "Advances in Databases and Information Systems, Seventh East European Conference, ADBIS 2003, Dresden, Germany, September 3-6, 2003", volume 2798 of Lecture Notes in Computer Science, pp. 236-252. - Springer, 2003.
13. Nagarkar P., Candan K. HCS: Hierarchical Cut Selection for Efficiently Processing Queries on Data Columns using Hierarchical Bitmap Indices. - In Proc. 17-th International Conference on Extending Database Technology (EDBT), March 24-28, 2014, Athens, Greece. pp. 271-282.
14. Nagarkar P., Candan K., Bhat A. Compressed Spatial Hierarchical Bitmap (cSHB) Indexes for Efficiently Processing Spatial Range Query Workloads. - In Proc. of the VLDB Endowment, Volume 8, Number 12, 2015, pp.1382-1393.
15. Otoo E., Wu K. Accelerating Queries on Very Large Datasets. - In book "Sceintific Data Management. Challenges, Technology and Deployment" (edited by Arie Shoshani, Doron Rotem), pp.183-234. - Chapman & Hall/CRC, 2010, 558 p.
16. Pieprzyk J., Morzy M., Comarch S. Mining Generalized Association Rules Using Prutax and Hierarchical Bitmap Index. - URL: www.cs.put.poznan.pl/mmorzy/papers/admkd07.pdf
17. Wu K., Madduri K., Canon S. Multi-Level Bitmap Indexes for Flash Memory Storage. - In Proc. of the 14-th International Database Engineering & Applications Symposium (IDEAS), 2010, pp.114-116.DOI: 10.1145/1866480.1866497.
18. Wojciechowski A., Wrembel R. On Index Structures for Star Query Processing in Data Warehouses. - In book "Business Intelligence. Third European Summer School, eBISS 2013, Dagsuhl Castle, Germany, July 7-12, 2013. Tutorial Lectures" (edited by Esteban Zimanyi), pp. 182-217. - Springer, 2014, 245 p. DOI 10.1007/978-3-319-05461-2
References
1. Venttsel' E.S. Teoriya veroyatnostei.-M.: Nauka, 1969.-576 s.
2. Kleinrok L. Teoriya massovogo obsluzhivaniya.-M.: Mashinostroenie, 1979.-432 s.
3. Larichev O. Teoriya i metody prinyatiya reshenii.-M.: Logos,2002.-392 s.
4. Podinovskii V.V. Vvedenie v teoriyu vazhnosti kriteriev v mnogokriterial'nykh zadachakh prinyatiya reshenii.-M.: Fizmatlit, 2007.-63 s.
5. Podinovskii V.V., Potapov M.A. Metod vzveshennoi summy kriteriev v analize mnogokriterial'nykh reshenii: PRO et CONTRA.-Biznes-Informatika, № 3(25), 2013.-s.41-48.
6. Sokolov A.V., Tokarev V.V. Metody optimal'nykh reshenii. T.1.-M.: Fizmatlit, 2011.-564 s.
7. Trub I.I. Analiticheskaya veroyatnostnaya model' bitmap-indeksov. //Programmnye sistemy i vychislitel'nye metody.-2016.-№4.-s.315-323. DOI: 10.7256/2305-6061.2016.4.21091
8. Trub I.I. Veroyatnostnaya model' ierarkhicheskikh indeksov baz dannykh. //Programmnye sistemy i vychislitel'nye metody.-2017.-№ 4.-s.15-31. DOI: 10.7256/2454-0714.2017.4.24437 URL: http://nbpublish.com/library_read_article.php?id=24437
9. Fedorov V.V. Chislennye metody maksimina.-M.: Nauka, 1979.-280 s.
10. Chmiel J., Morzy T., Wrembel R. HOBI: Hierarchically Organized Bitmap Index for Indexing Dimensional Data. - In Proc. of the Eleventh International Conference on Data Warehousing and Knowledge Discovery (DaWaK), August, 2009, pp. 87-98. DOI: 10.1007/978-3-642-03730-6_8
11. Kim J.W. Binning Strategy for Hierarchical Bitmap Indices with Large Scale Domain Hierarchy. - International Journal of Applied Engineering Research, Volume 11, Number 18 (2016), pp.9289-9296.
12. Morzy M., Morzy T., Nanopoulos A., Manolopoulos Y. Hierarchical Bitmap Index: an Efficient and Scalable Indexing Technique for Set-Valued Attributes. - In Proc. "Advances in Databases and Information Systems, Seventh East European Conference, ADBIS 2003, Dresden, Germany, September 3-6, 2003", volume 2798 of Lecture Notes in Computer Science, pp. 236-252. - Springer, 2003.
13. Nagarkar P., Candan K. HCS: Hierarchical Cut Selection for Efficiently Processing Queries on Data Columns using Hierarchical Bitmap Indices. - In Proc. 17-th International Conference on Extending Database Technology (EDBT), March 24-28, 2014, Athens, Greece. pp. 271-282.
14. Nagarkar P., Candan K., Bhat A. Compressed Spatial Hierarchical Bitmap (cSHB) Indexes for Efficiently Processing Spatial Range Query Workloads. - In Proc. of the VLDB Endowment, Volume 8, Number 12, 2015, pp.1382-1393.
15. Otoo E., Wu K. Accelerating Queries on Very Large Datasets. - In book "Sceintific Data Management. Challenges, Technology and Deployment" (edited by Arie Shoshani, Doron Rotem), pp.183-234. - Chapman & Hall/CRC, 2010, 558 p.
16. Pieprzyk J., Morzy M., Comarch S. Mining Generalized Association Rules Using Prutax and Hierarchical Bitmap Index. - URL: www.cs.put.poznan.pl/mmorzy/papers/admkd07.pdf
17. Wu K., Madduri K., Canon S. Multi-Level Bitmap Indexes for Flash Memory Storage. - In Proc. of the 14-th International Database Engineering & Applications Symposium (IDEAS), 2010, pp.114-116.DOI: 10.1145/1866480.1866497.
18. Wojciechowski A., Wrembel R. On Index Structures for Star Query Processing in Data Warehouses. - In book "Business Intelligence. Third European Summer School, eBISS 2013, Dagsuhl Castle, Germany, July 7-12, 2013. Tutorial Lectures" (edited by Esteban Zimanyi), pp. 182-217. - Springer, 2014, 245 p. DOI 10.1007/978-3-319-05461-2
|
 Рус
Рус