|
Кибернетика и программирование
Правильная ссылка на статью:
Райхлин В.А., Минязев Р.Ш., Классен Р.К.
Эффективность консервативных СУБД больших объемов на кластерной платформе
// Кибернетика и программирование.
2018. № 5.
С. 44-62.
DOI: 10.25136/2644-5522.2018.5.22301 URL: https://nbpublish.com/library_read_article.php?id=22301
Эффективность консервативных СУБД больших объемов на кластерной платформе
Райхлин Вадим Абрамович
доктор физико-математических наук
профессор, кафедра Компьютерных систем, Казанский национальный исследовательский технический университет им. А.Н. Туполева — КАИ
1420111, Россия, республика Татарстан, г. Казань, ул. К. Маркса, 10
Raikhlin Vadim Abramovich
Doctor of Physics and Mathematics
Professor, Department of Computer Systems, Tupolev Kazan National Research Technical University
1420111, Russia, respublika Tatarstan, g. Kazan', ul. K. Marksa, 10

|
no-form@evm.kstu-kai.ru
|
|
 |
Минязев Ринат Шавкатович
кандидат технических наук
доцент, кафедра Компьютерных систем, Казанский национальный исследовательский технический университет им. А.Н. Туполева — КАИ
1420111, Россия, республика Татарстан, г. Казань, ул. К. Маркса, 10
Minyazev Rinat Shavkatovich
PhD in Technical Science
Associate Professor, Department of Computer Systems, Tupolev Kazan National Research Technical University
1420111, Russia, respublika Tatarstan, g. Kazan', ul. K. Marksa, 10
|
|
txf13@mail.ru
|
|
 |
|
Классен Роман Константинович
аспирант, кафедра Компьтерных систем, Казанский национальный исследовательский технический университет им. А. Н. Туполева — КАИ
420111, Россия, республика Татарстан, г. Казань, ул. К.маркса, 10
Klassen Roman Konstantinovich
Postgraduate Student, Department of Computer Systems, Tupolev Kazan National Research Technical University
420111, Russia, respublika Tatarstan, g. Kazan', ul. K.marksa, 10
|
|
klassen.rk@gmail.com
|
|
 |
|
DOI: 10.25136/2644-5522.2018.5.22301
Дата направления статьи в редакцию:
14-03-2017
Дата публикации:
25-11-2018
Аннотация:
Обсуждаются результаты оригинальных исследований принципов организации и особенностей функционирования консервативных СУБД кластерного типа. Актуальность принятой ориентации на работу с базами данных больших объемов определяется современными тенденциями интеллектуальной обработки больших информационных массивов. Повышение объема баз данных требует их хеширования по узлам кластера. Это обуславливает необходимость использования регулярного плана обработки запросов с динамической сегментацией промежуточных и временных отношений. Дается сравнительная оценка получаемых результатов с альтернативным подходом "ядро на запрос" при условии репликации БД по узлам кластера. Значительное место в статье занимает теоретический анализ возможностей GPU-акселерации применительно к консервативным СУБД с регулярным планом обработки запросов. Экспериментальные исследования проводились на специально разработанных натурных моделях — СУБД Clusterix, Clusterix-M, PerformSys с применением средств MySQL на исполнительном уровне. Теоретический анализ возможностей GPU-акселерации выполнен на примере предлагаемого проекта Clusterix-G. Показаны: особенности поведения СУБД Clusterix в динамике и оптимальный архитектурный вариант системы; повышение "в разы" масштабируемости и производительности системы при переходе к мультикластеризации (СУБД Clusterix-M) либо к перспективной технологии «ядро на запрос» (PerformSys); неконкурентоспособность GPU-акселерации в сравнении с подходом «ядро на запрос» для баз данных средних объемов, не превышающих размеры оперативной памяти узла кластера, но не умещающихся в глобальной памяти графического процессора. Для баз данных больших объемов предложена гибридная технология (проект Clusterix-G) с разделением кластера на две части. Одна из них выполняет селектирование и проецирование над хешированной по узлам и сжатой базой данных. Другая – соединение по схеме «ядро на запрос». Функции GPU-ускорителей в разных частях своеобразны. Теоретический анализ показал бόльшую эффективность такой технологии в сравнении с Clusterix-M. Но вопрос о целесообразности использования графических ускорителей в рамках подобной архитектуры требует дальнейшего экспериментального исследования. Отмечено, что проект Clusterix-M сохраняет жизнеспособность в области Big Data. Аналогично — с подходом «ядро на запрос» при доступности использования современных дорогих информационных технологий.
Ключевые слова:
Консервативные СУБД, Большие данные, Регулярный план обработки, Хеширование по узлам, Динамическая сегментация отношений, Масшабируемость, Производительность, Мультикластеризация, Перспективная технология, Эффективность графических ускорителей
УДК: 681.3
Abstract: The results of original research on the principles of organization and features of the operation of conservative DBMS of cluster type are discussed. The relevance of the adopted orientation to work with large-scale databases is determined by modern trends in the intellectual processing of large information arrays. Increasing the volume of databases requires them to be hashed over cluster nodes. This necessitates the use of a regular query processing plan with dynamic segmentation of intermediate and temporary relationships. A comparative evaluation of the results obtained with the alternative "core-to-query" approach is provided, provided that the database is replicated across cluster nodes. A significant place in the article is occupied by a theoretical analysis of GPU-accelerations with respect to conservative DBMS with a regular query processing plan. Experimental studies were carried out on specially developed full-scale models - Clusterix, Clusterix-M, PerformSys with MySQL at the executive level. Theoretical analysis of the GPU-accelerations is performed using the example of the proposed project Clusterix-G. The following are shown: the peculiarities of the behavior of the Clusterix DBMS in dynamics and the optimal architectural variant of the system; Increased "many times" scalability and system performance in the transition to multiclustering (DBMS Clusterix-M) or to the advanced technology "core-to-query" (PerformSys); Non-competitiveness of GPU-acceleration in comparison with the "core-to-query" approach for medium-sized databases that do not exceed the size of the cluster's memory, but do not fit into the GPU's global memory. For large-scale databases, a hybrid technology (the Clusterix-G project) is proposed with the cluster divided into two parts. One of them performs selection and projection over a hashed by nodes and a compressed database. The other is a core-to-query connection. Functions of GPU accelerators in different parts are peculiar. Theoretical analysis showed greater effectiveness of such technology in comparison with Clusterix-M. But the question of the advisability of using graphic accelerators within this architecture requires further experimental research. It is noted that the Clusterix-M project remains viable in the Big Data field. Similarly - with the "core-to-query" approach with the availability of modern expensive information technologies.
Keywords: Conservative DBMS, Big Data, Regular processing plan, Host hashing, Dynamic relationship segmentation, Scalability, Performance, Multiclusterisation, Advanced technology, GPU-accelerators efficiency
Используемые обозначения – Clusterix, Clusterix-M, Clusterix-G– названия затрагиваемых в статье проектов консервативных СУБД на кластерной платформе, принятые разработчиками этих проектов.
– MySQL – применяемая в этих проектах инструментальная СУБД.
– PerformSys («ядро на запрос», «узел на множество запросов») – перспективная технология консервативных СУБД.
– GPU(Graphics Processing Unit) – сопроцессор, широко применяемый как ускоритель трехмерной графики. Используется и при выполнении обычных вычислений – подход GPGPU (General-Purpose GPU).
– CPU – центральный процессор.
– TPC(Transaction Processing Performance Council) – Совет по производительности обработки транзакций.
– TPC-H – один из тестов производительности систем принятия решений. Введение Проблема масштабируемости по числу узлов кластера и повышения производительности всегда была и остается одной из серьезнейших проблем параллельных СУБД [1-4]. В настоящее время имеется немалое число разработок таких СУБД на платформе вычислительных кластеров. Большинство из них осуществляет поддержку работы internet-сервисов, выполняющих сравнительно простые операций типа selectи insertнад динамически изменяемыми базами данных. Причина в том, что повышение скорости обработки сложных запросов до сих пор проблематично [5]. Наше рассмотрение ориентировано на построение параллельных СУБД консервативного типа (с эпизодическим обновлением данных в специально выделяемое время) больших объемов (до единиц TB). Его актуальность определяется тенденциями интеллектуальной обработки информационных массивов. Примером тому является проект специализированной системы SciDB для обработки научных данных (результатов испытаний, наблюдений за состоянием среды и др.) [6-8]. Для них характерен высокий удельный вес именно сложных запросов типа select – project – join, оперирующих множеством таблиц с большим числом операций соединения join. Такие базы данных приходится хешировать по узлам кластера.
Поэтому единственно приемлемым планом обработки запросов оказывается регулярный [9] (рис.1) по схеме
СЕЛЕКЦИЯ (σ) – ПРОЕКЦИЯ (π) – СОЕДИНЕНИЕ (σθ(R x S)) .
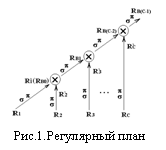 Здесь < x > – декартово произведение, селектирование в операции соединения ведется по θ‑соответствию кортежей отношений R и S. По условиюсоединение всегда естественное и проводится по полям первичного ключа. При использовании стратегии «множество узлов кластера – на один запрос» база данных оказывается распределенной по узлам. Получение любого промежуточного Ri' и любого временного RB(i-2) отношений происходит параллельно. При этом теоретически возможно совмещение обоих процессов, если за время съема с дисков и предварительной обработки (селекции с проекцией) исходного отношения Riуспевает сформироваться временное отношение RB(i-2). Для целей исследования была разработана натурная модель – СУБД Clusterix[10]. Здесь < x > – декартово произведение, селектирование в операции соединения ведется по θ‑соответствию кортежей отношений R и S. По условиюсоединение всегда естественное и проводится по полям первичного ключа. При использовании стратегии «множество узлов кластера – на один запрос» база данных оказывается распределенной по узлам. Получение любого промежуточного Ri' и любого временного RB(i-2) отношений происходит параллельно. При этом теоретически возможно совмещение обоих процессов, если за время съема с дисков и предварительной обработки (селекции с проекцией) исходного отношения Riуспевает сформироваться временное отношение RB(i-2). Для целей исследования была разработана натурная модель – СУБД Clusterix[10].
1. СУБД Clusterix Функциональная характеристика. Обработка запросов – 2-уровневая. На нижнем уровене выполняются операции селекции (σ) и проекции (π) над исходными отношениями Riбазы данных. Результатом обработки этого уровня является промежуточное отношение Ri'. На верхнем уровне реализуется операция соединения RBi–1 = Ri' ►◄ RBi–2 = π (σθ(Ri'xRBi–2)), где RBi–1 и RBi–2 – временные отношения как результаты соединений в i- и в (i-1)-шагах соответственно. Фильтрация на нижнем уровне значительно снижает объемы данных, передаваемых на верхний уровень.
Отношения БД распределены по дискам на процессорах нижнего уровня (IOr) с применением хеш-функции к первичному ключу для каждого кортежа отношения. Требованию равномерного распределения кортежей хорошо удовлетворяет выбор в качестве нее функции деления по модулю [11]. Основание деления – число процессоров нижнего уровня (nIO). Остаток от деления r однозначно определяет номер страницы (процессора IOr), куда будет распределен кортеж. Процессоры верхнего уровня обработки запроса называются процессорами JOIN. Хеш-функция, использованная в Clusterix, имеет следующий вид:
hash=((key_field1 mod M) + (key_field2 mod M) + … + (key_fieldP mod M)) mod M,
где P – количество полей в первичном ключе; M = nIO– основание деления по модулю; mod – операция деления по модулю. Как показали эксперименты на примере теста TPC-H (M=2,3,4,6,8,12,16,18,24), данный подход обеспечивает достаточно равномерное распределение данных по страницам. Хешированные страницы хранятся на узлах IOr в виде отношений базы данных tpchK, где K = r.
Кроме исполнительных процессоров (IOr и JOINj), есть еще два процессора. Процессор УПР реализует функции мониторинга и управления остальными процессорами системы. Для реализации функций объединения результатов обработки с уровня JOIN введен процессор SORT. Он дополнительно выполняет функции агрегации (SUM(), AVG(), MAX(), MIN() и др.) и сортировки результата предшествующей операции соединения. В Clusterix реализован вариант совместной работы процессоров УПР и SORT на Host ЭВМ. Работа на уровне файловой системы, системных буферов, алгоритмов доступа к данным, работы с индексами и т.п. реализуется с помощью стандартной СУБД MySQL.
Система реализует потоково-конвейерный механизм обработки запросов. Конвейерность достигается за счет совмещения работ на нижнем, верхнем уровнях обработки и на уровне SORT (рис.2). Так реализуется вертикальный параллелизм. Его особенностью является совмещение последней операции на уровне JOIN для одного запроса и первой операции на уровне IO для следующего.

В Clusterix реализуется и горизонтальный параллелизм, который достигается параллельной работой нескольких процессоров одного уровня над разными частями данных одного и того же запроса. Применение динамической сегментации промежуточных и временных отношений позволяет реализовать параллельное выполнение операции соединения на множестве процессоров JOINj. Для обеспечения надежной работы системы на всех уровнях применена барьерная синхронизация.
Программная система. Параллельная СУБД Clusterixпредставляет композицию четырех программных модулей: mlisten, msort, irun, jrun. Модуль mlistenреализует функцию логического процессора УПР, модуль msort– SORT, модуль irun– IO, модуль jrun– JOIN. Модули mlisten и msortфункционируют на Host. Назначение модуля mlisten: получение входного запроса от пользователя и передача результатов обработки обратно; пересылка команд управления модулям irun, jrun, msort; мониторинг работы модулей системы; сбор статистической информации. Модуль msortпредназначен для выполнения операции объединения результатов обработки JOIN с последующим выполнением операций агрегации и сортировки результата. Назначение модуля irun – выполнение операций селекции и проекции над исходными отношениями базы данных. На каждом узле уровня IO располагается своя страница исходной БД. Номер этой страницы определяется текущей конфигурацией и присваивается ей при запуске системы. Поэтому каждая страница (и соответствующий ей модуль irun) имеет уникальный номер. То же – и с модулем jrun, который выполняет операции соединения. Количество модулей irunи jrunдля любой конфигурации одинаково. Число физических процессоров, на которых функционируют программные модули irunи jrun, может быть различно.
Моделирование процессов, протекающих в Clusterix, выполнялось при разном числе узлов кластера (физических процессоров) и разном распределении в них программных модулей (логических процессоров). Здесь и далее понятия «логический процессор» и «программный модуль» (irunили jrun) используются как синонимы. На каждом физическом процессоре могут выполняться несколько логических. Общее количество физических процессоров в кластере (включая Host) N=2n+1, где n=1,2,… Величина 2n = p+q, p и q – числа физических процессоров IO и JOIN. В дальнейшем фигурирует их отношение k = q/p.
Рассматривались три типа конфигураций Clusterix: «линейка», «симметрия» и «асимметрия». В конфигурации «линейка» (с условным значением k=0) на каждом физическом процессоре кластера выполняются оба логических процессора: irunи jrun. Модули функционируют в режиме разделения времени при условии барьерной синхронизации. Сихронизация выполняется передачей коротких сетевых сообщений и осуществляется модулем mlisten. Каждый узел кластера имеет устройство внешней памяти. Для конфигурации «симметрия» характерна реализация каждого логического процессора на отдельном физическом процессоре. Любому узлу, на котором выполняется модуль irun, соответствует узел с модулем jrun. Числа узлов JOIN и IO одинаковы: p=q=n, k=1. Конфигурации «асимметрия» предназначена для моделирования таких нагрузок, при которых основная часть работ приходится на узлы IO. Поэтому количество физических процессоров IO больше по сравнению с числом физических процессоров JOIN. На каждом физическом процессоре JOIN выполняется несколько логических процессоров jrun. Исследования показали, что количество совместно работающих логических процессоров jrunна одном узле не должно превышать трех. Поэтому здесь k=1/2, 1/3.
Запросы, на которых проводится тестирование, размещаются в специальном интерфейсном отношении queryсистемной базы данных в оттранслированном виде для каждого из трех программных модулей: irun, jrun и msort. Программа-клиента посылает номер SQL-запроса. Модуль mlistenзапускает для обработки запроса функцию-поток Процесс h, где h – порядковый номер запроса в системе. Процесс h считывает пакет команд запроса из отношения queryи передает его соответствующим модулям для исполнения.
Анализ экспериментальных данных. В качестве представительского теста (ПТ) использовался ограниченный тест TPC-H из 14 запросов, не содержащих операций записи. Далее приводятся результаты модельного эксперимента на натурной модели – СУБД Clustrerix, полученные для двух кластерных платформ [12,13]:
– Платформа 1. Host – cервер Intel Core 4 Xeon 5320 (2,4 GHz, RAM 4GB). Исполнительные узлы – 13 ПК Intel Core 2 Duo 6320 (1,87 GHz, RAM 3GB, жесткий диск SATA 125GB); локальная сеть GigabitEthernet. На каждый компьютер установлена операционная система Linux. Все процессоры дополнительно оснащены СУБД MySQL.
– Платформа 2. Вычислительный кластер фирмы SUN из 22 узлов 2 Quad-core Intel Xeon E5450 CPU/1,87GHz/32GB. Интерконнект между узлами – GigabitEthernet/Infiniband 4X (20Gbps DDR) с 24-портовыми коммутаторами Cisco. Дисковая подсистема узла – SAS диски XRB-SS2CD-146G10KZ с пропускной способностью 300 МB/s. Как и ранее, – Linux, MySQL.
На рис.3a,b приведены экспериментальные зависимости производительности, полученные усреднением на 5 вариантах перестановок запросов ПТ для платформы 1 и разных объемов баз данных.
|
a

| |
 Рус
Рус










