|
Историческая информатика
Правильная ссылка на статью:
Шпирко С.В.
Еще раз к вопросу об оценивании численности генуэзского купечества в Византии конца XIII века с помощью методов математической статистики
// Историческая информатика.
2022. № 1.
С. 63-73.
DOI: 10.7256/2585-7797.2022.1.37362 URL: https://nbpublish.com/library_read_article.php?id=37362
Еще раз к вопросу об оценивании численности генуэзского купечества в Византии конца XIII века с помощью методов математической статистики
Шпирко Сергей Валерьевич
кандидат физико-математических наук, кандидат исторических наук
доцент, Российский Государственный Гуманитарный Университет, Историко-Архивный институт
119313, Россия, г. Москва, Ленинский проспект, 88, корп. 3
Shpirko Sergey
Associate Professor, Moscow State Historical Archives Institute, Russian State University for the Humanities
119313, Russia, g. Moscow, ul. Leninskii Prospekt, 88 korpus 3, kv. 122

|
shpirkos@mail.ru
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2585-7797.2022.1.37362
Дата направления статьи в редакцию:
20-01-2022
Дата публикации:
11-05-2022
Аннотация:
Одной из актуальных проблем византинистики является оценка численности генуэзской торговой общины Константинополя, игравшей критически важную роль в судьбе поздней Византии. Еще 30 лет назад историком А.Л. Пономаревым для решения этой проблемы было предложено использовать математические методы на основе данных косвенных источников– нотариальных актов, сохранившихся в Государственном архиве Генуи. Эти акты составлялись для фиксации коммерческих сделок, соглашений о создании торговых товариществ, наймов судов, завещаний, купли и продажи домов, товаров и людей. Формуляр акта имеет довольно однородную структуру. Помимо обязательного упоминания в тексте имен договаривающихся сторон и свидетелей сделки, он также может в зависимости от ее типа содержать имена опекунов, получателей завещания и других третьих лиц. Таким образом, эти данные по клиентеле генуэзских нотариев представляют из себя довольно внушительный и ценный массив информации, который может косвенным образом свидетельствовать о численности всей торговой генуэзской общины Византии. Для решения поставленной задачи автор настоящей статьи привлекает идеи и методы теории случайных размещений, являющейся интенсивно развивающимся направлением математической статистики. Он основан на построении линейной оценки для искомой величины и предполагает случайность выборки (в данном примере это сведения о клиентах-купцах). Полученный результат сравнивается с оценкой из предыдущей статьи автора, которая основана на другом методе математической статистики и достаточно близка к числу А.Л. Пономарева – 688 человек.
Ключевые слова:
Константинополь, генуэзцы, нотариальные акты, частота упоминания, ранжированный ряд, статистическое оценивание, случайная выборка, объем конечной совокупности, линейная оценка, случайные размещения
Abstract: One of the actual problems of Byzantine studies is the estimation of the size of the Genoese trading community of Constantinople, which played a critical role in the fate of late Byzantium. To solve this problem the historian A.L. Ponomarev proposed to use mathematical methods based on data from indirect sources - notarial deeds preserved in the State Archives of Genoa. These deeds were drawn up to fix commercial transactions, agreements on the creation of commercial partnerships, the hiring of ships, wills, the purchase and sale of houses, goods and people. In addition to the obligatory mention in the deed form of the names of the contracting parties and witnesses to the transaction, it may also, depending on its type, contain the names of guardians, recipients of the will and other third parties. Thus, these data on the clientele of Genoese notaries represent a rather impressive and valuable array of information, which may indirectly indicate the size of the entire trading Genoese community of Byzantium. To solve this problem, the author of this paper draws on the ideas and methods of the theory of random placements, which is an intensively developing area of mathematical statistics. It is based on constructing a linear estimate of the value and assumes a random sample. The result obtained is compared with the estimate from the previous paper by the author, which is based on another method of mathematical statistics and is quite close to the value of A.L. Ponomarev - 688 people.
Keywords: Constantinople, Genoese, notarial deeds, frequency of occurrence, ranged series, statistical estimation, sample, size of a finite population, linear estimate, random placement
I. Введение
Возможно ли применять методы и идеи математических наук к задаче восполнения данных исторических источников? В частности, такой вопрос ставит А.Л. Пономарев в своих исследованиях, связанных с установлением приблизительной численности генуэзского купечества в Константинополе конца XIII века.
В историографии хорошо известно, что, начиная c заключения в 1261 году Нимфейского договора, генуэзцы развили бурную коммерческую деятельность в византийских владениях, о чем свидетельствуют многочисленные договора о торговых товариществах, наймах судов, завещаний, купли и продажи домов, товаров и людей. Однако о численности их торговой общины исторические источники не сохранили прямых свидетельств. А.Л. Пономарев предлагает использовать для этой цели данные косвенных источников, а именно многочисленные нотариальные акты, хранящиеся в Государственном архиве Генуи. К ним, в частности, относятся 149 актов нотария Габриэле де Предоно, составленные в Пере (центре генуэзской общины Константинополя и второй по значимости после Каффы колонии генуэзцев в византийских владениях) за период с июня по октябрь 1281 года и опубликованные румынским ученым Г. Брэтиану в 1927 году [1].
Все акты составлены в соответствии с четким протоколом, содержат помимо всего прочего имена контрагентов, свидетелей, а также третьих лиц, причастных к коммерческой сделке. При этом, одно и то же лицо могло быть указано в нескольких актах. Например, в одном договоре оно выступает в роли контрагента, в другом – в роли свидетеля, в третьем– в роли покупателя раба. Конечно, акты Предоно не содержат имена всех членов генуэзской торговой общины Перы. Купцы могли заключать сделки и у других нотариев. Например, только в Каффе (правда, в десятых годах XV века) трудилось как минимум 14 нотариев [2, c. 8]. Мелкие сделки могли вообще не регистрироваться. Однако, если исходить из гипотезы о случайности выбора купцом того или иного нотария для фиксации сделки, то данные Предоно могут служить “мгновенным снимком”, позволяющим решить искомую задачу оценивания всей численности.
Итак, задачей нашего моделирования является оценка объема генеральной совокупности по имеющейся выборке. Причем, в основе данного моделирования лежит представление о процессе составления нотарием акта и упоминания в нем отдельных персоналий как выборе соответствующих элементов из генеральной (общей) совокупности. Поскольку одни и те же персоналии могут упоминаться в нескольких актах, то такой процесс является выбором с возвращением.
В предыдущей работе мы исследовали распределение числа различных элементов, попавших в выборку, как случайной величины. Если все элементы совокупности имеют равные шансы при очередном испытании попасть в выборку (случайность выборки), то формула совместной вероятности этой величины хорошо известна. При этом, данная функция зависит от оцениваемой величины объема совокупности как от своего параметра. Подставляя в формулу реальные данные и максимизируя ее по этому параметру, мы получаем наиболее “правдоподобную” оценку для оцениваемой величины [3].
В настоящей работе мы отталкиваемся от данных по частотам упоминаний персоналий в актах. А для решения задачи оценивания объема всей совокупности привлекается интенсивно развивающийся с середины 1960-х годов подход в математической статистике, связанный со случайными размещениями. В соответствии с данным подходом, мы будем оперировать с набором статистик, представляющими из себя как раз частоты встречаемости наблюдаемых элементов выборки. С помощью этих статистик мы построим линейную оценку, которая оказывается несмещенной для оцениваемой величины общего числа клиентов-купцов.
II. Задача оценивания
Обозначим через n – объем выборки, а через N – объем всей совокупности, который нам предстоит оценить. Поскольку выборка извлечена из совокупности по схеме случайного выбора с возвращением, в ней могут быть повторяющиеся элементы. Обозначим через μr число наблюдавшихся элементов, каждый из которых повторился ровно r раз, r=1,..,n.
Наша задача состоит в том, что использовать информацию, заключенную в наборе статистик (μ1, μ2,..,μn), для оценивания неизвестной величины N. Нетрудно проверить, что все эти статистики связаны соотношением μ1+ 2 μ2 +3 μ3 +..+ n μn =n. Поэтому одна из статистик может быть выражена через все остальные. С учетом этого замечания, ограничимся в дальнейшем рассмотрением укороченного набора (μ2,..,μn).
Следуя логике [4], будем искать решение в классе линейных несмещенных оценок, причем оценивать будем не N, а обратную ей величину 1/N. То есть, искомая оценка  является линейной комбинацией статистик (μ2,..,μn), а ее математическое ожидание должно в точности совпадать с 1/N: является линейной комбинацией статистик (μ2,..,μn), а ее математическое ожидание должно в точности совпадать с 1/N:


В формуле (1) через Σ обозначена операция суммирования по индексу r, пробегающему значения от 2 до n, а в (2) через E – математическое ожидание (среднее значение) случайной величины 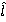 . .
Необходимо указать на отличие настоящего подхода от того, который был продемонстрирован нами ранее. Если в [3] искомая величина N определяется из принципа максимального правдоподобия, то есть из формулы для наиболее вероятного ее значения (моды), то в настоящей статье мы оперируем в терминах математического ожидания.
Мода, как и математическое ожидание, являются важными характеристиками случайной величины. В общем случае (когда распределение несимметрично) они не совпадают друг с другом, что демонстрируется на рис.1, где величина математического ожидания будет смещена относительно моды (влево):

Рис. 1 Мода и мат.ожидание дискретной случайной величины (обозначены буквами М и E соответственно)
Таким образом, привлечение этих двух подходов позволяет независимым образом уточнить диапазон возможных значений искомой величины.
Как видно из формул (1)-(2), для вычисления коэффициентов lr необходимо найти математическое ожидание случайных величин μr, r =2,..,n. Изящный вывод формулы для E μr приводится в [5]. Для начала, перейдем от исходного выбора с возвращением к эквивалентной схеме равновероятного размещения, в которой n частиц независимо друг от друга размещаются по N ячейкам.
Обозначим через θir индикатор, принимающий единичное значение, если ровно r частиц попали в i-ю ячейку, и ноль – в противном случае. В этом случае статистику μr можно представить в виде суммы соответствующих индикаторов: 
Тогда, с учетом независимости индикаторов друг от друга получаем

где через P(θir = 1) обозначена вероятность того, что соответствующий индикатор примет единичное значение.
Если вероятность попадания одной частицы в фиксированную ячейку равна 1/N, то r частиц попадут в нее с вероятностью (1/N)r. Отсюда нетрудно заключить, что вероятность попадания n-r частиц в оставшиеся N-1 ячеек составит ((N-1)/N)n-r=(1-1/N)n-r.
Количество всевозможных способов выбора r частиц из n известно и определяется формулой числа сочетаний 
Отсюда, применяя теорему о сложении вероятностей, приходим к формуле для математического ожидания случайных величин μr:

Тогда, с учетом (1), формула (2) для оценки представляется в следующем виде:

Умножим обе части получившегося уравнения на величину N. Сокращая в его левой части одинаковые множители, получаем

Применяя бином Ньютона (см. Приложение 1), находим из (3) формулу для коэффициентов оценки , впервые полученную в [4]:

Возвращаясь к (1), отсюда окончательно получаем

Полученная формула позволяет перейти к задаче оценивания численности по актам Предоно.
III. Численное моделирование
Предварительным этапом для моделирования численности является идентификация приводимых в актах имен. Проведение данной процедуры затрудняет то, что некоторые персоналии фигурируют под несколькими, пусть и довольно похожими, именами, как, например, Ogerius [1, с.89], Ogerinus [1, с.91]. Более того, одно и то же лицо может выступать в актах и в разных ролях. Так, тот же Ogerius в одних договорах комменды выступает в качестве трактатора (accomendatarius, то есть партнера, получающего средства от коммендатора для ведения торговли в установленном месте), в других договорах – в роли свидетеля, а в актах завещания – в роли получателя по завещанию. В таких случаях лишь дополнительное указание профессии или должности (например, placerius peliparius) позволяет идентифицировать их как одно лицо [6].
Всего в актах было идентифицировано 447 персоналий, которые были упомянуты 866 раз (сюда включены и женщины). В то же время, рабы, как объекты сделок купли/продажи, в рассмотрение не брались. Ниже приведен график частот упоминания отдельных персоналий, упорядоченный по неубыванию:

Рис. 2 Ранжированный ряд упоминаний персоналий в актах Предоно 1281 года
Так, первому рангу (максимальная частота – 68 упоминаний) соответствует одно лицо – нотарий Guglielmo Gandulfi, почти постоянно привлекавшийся в качестве свидетеля договора. Все остальные лица упоминаются существенно меньшее число раз. Так, ровно по одному разу (наибольший ранг) упоминаются 318 персон. Для большей наглядности соответствующие статистики приводятся в следующей таблице:
Таблица 1. Распределение числа персоналий по частоте упоминания

Примечание: μr – количество персоналий, упоминаемых ровно r раз.
Простое визуальное наблюдение частот упоминания не позволяет сделать вывод о случайности данных выборки, что подтверждается и рассмотрением критерия χ2 (хи-квадрат). Для обеспечения корректности процедуры оценивания в предыдущей нашей статье [3] предлагается перейти от исходной к рассмотрению усеченной выборки, в которой исключаются редкие данные, соответствующие высоким частотам встречаемости.
Так, если убрать из рассмотрения первые по частоте 10 персоналий (с частотами встречаемости от 68 до 9), то с уровнем значимости 0,1 данную выборку уже можно считать случайной. После удаления этих 10 элементов объем n выборки сокращается с 866 до 700, а число различных элементов i в ней становится равным соответственно 437 (вместо прежних 447). При этом, рассчитанное по формуле значение χ2 статистики равно 448,6857, что меньше соответствующего квантиля, равного 475,2005 [7, с. 577]. Все это позволяет перейти к оцениванию объема N генеральной совокупности.
Обращаясь к формуле (4), получаем N=439. Эта цифра ниже оценки на тех же данных, полученной в [3] (N=688). Отметим, что примерно такую же оценку для численности (N=645–650) дает подход А.Л. Пономарева, основанный на модификации эмпирического закона Ципфа [8,9]. Подобное расхождение (439 против 688 человек) требует дополнительного разбирательства.
IV. Сравнение результатов моделирования
Прежде всего, попробуем продвинуться в направлении дальнейшего усечения выборки. Так, после удаления из рассмотрения еще 15 персоналий (с частотами встречаемости от 8 до 6) объем выборки сокращается с 700 до 600, а число различных элементов i в ней уменьшается соответственно с 437 до 422. Применение первого подхода (из [3]) дает оценку в 823 человека, а второго (из настоящей статьи) – 660 человек. Результаты дальнейшего применения аналогичной процедуры удобно свести в следующую таблицу:
Таблица 2. Оценивание численности общины по распределению числа персоналий по частоте упоминания

Примечание: Через «метод I» обозначен метод из [3], а через «метод II» – из настоящей статьи. В данную таблицу включены также результаты моделирования А.Л. Пономарева из статей [8,9].
Анализ таблицы 2 показывает, что по мере усечения объема выборки оценки обоих методов (метод I и метод II) имеют тенденцию к увеличению и взаимному сближению своих значений, вплоть до пересечения соответствующих графиков, что удобно продемонстрировать на следующем рисунке:

Рис. 3 Оценивание численности всей общины согласно методам I и II
Что касается метода II, укажем на близость его результатов при объеме n выборки в 600 (при числе различных элементов i=422) с результатами А.Л. Пономарева (при числе различных элементов i=507).
В ситуации выбора между методом I и методом II полезным представляется сравнить результаты работы обоих методов на каких-либо простых и однозначных примерах, абстрагировавшись от конкретики решаемой задачи.
Пример 1. Пусть генеральная совокупность состоит из одного единственного элемента (N=1). Из нее выбором с возвращением извлекается этот элемент сто раз n (n=100). Понятно, что все элементы совпадают, и число различных элементов равняется единице (i=1). Рассмотрим результаты оценивания, которые будут давать оба метода. Напомним, что первый метод (метод I) основывается на максимизации функции правдоподобия

где через  обозначено число сочетаний из N по i: обозначено число сочетаний из N по i:  . Если подставить сюда конкретные значения i и n, то нетрудно подсчитать, что . Если подставить сюда конкретные значения i и n, то нетрудно подсчитать, что  . Своего максимума эта функция достигает при минимальном значении N, равном единице, что совпадает с его истинным значением. . Своего максимума эта функция достигает при минимальном значении N, равном единице, что совпадает с его истинным значением.
Теперь получим оценку для N согласно второму методу (метод II). В его терминах число элементов, повторившихся ровно r=n раз, равняется единице (μr=1). Подставляя эти значения в формулу (4), получаем

то есть и здесь приближенная оценка совпадает с истинной: N=1.
Пример 2. Немного усложним предыдущий пример. Пусть теперь генеральная совокупность состоит из десяти элементов (N=10). Из нее выбором с возвращением извлекается по одному элементу, как и ранее, 100 раз (n=100). При этом, в сформированной выборке присутствуют все эти десять элементов, причем, в равном количестве. В наших терминах это равносильно i=10, r=10 и μr=10.
Нетрудно проверить, что применение метода с максимизацией функции правдоподобия (метод I) дает точную оценку N=10. Подставим теперь конкретные значения в формулу (4) для второго метода:

откуда мы получаем приближенную оценку для N=11.
Итак, можно констатировать, что второй метод в некоторых случаях (причем, довольно простых) дает менее точные оценки, чем первый метод. Данный факт можно объяснить, на наш взгляд, тем, что во втором методе оценивается не сама величина N, а обратная к ней  . В случае, когда достаточна мала, обращаемая величина ведет себя очень не устойчиво из-за ошибок округления. По-видимому, такое происходит и в нашем конкретном случае. . В случае, когда достаточна мала, обращаемая величина ведет себя очень не устойчиво из-за ошибок округления. По-видимому, такое происходит и в нашем конкретном случае.
Для демонстрации этого утверждения вернемся опять к случаю, когда из исходной выборки изъяты первые десять элементов по частоте встречаемости (n=700, i=437). Подстановка конкретных значений в формулу (4) для дает значение, равное 0,002329859. Для оценивания величины N нам нужно, естественно, обратить последнюю величину, получив значение 429.
Насколько неустойчива эта оценка можно судить по тому, что если округлить значение с точностью до одной тысячной (до 0,002), то обратное ей значение будет равняться 500 (вместо 429). То есть, ничтожно малое изменение приводит к изменению оцениваемой величины на десятки единиц.
Резюмируя вышесказанное, можно сказать, что к применению второго метода надо относиться с осторожностью, и в данном конкретном случае отдать предпочтение оценке, получаемой первым методом, то есть оценивать численность купеческой общины Перы конца XIII в. приблизительно в 688 человек. В то же время, второй метод, апробированный в данной статье, может быть полезным для подобных исследований на другой источниковой базе.
Приложение 1.
Для нахождения коэффициентов lr из уравнения (3) воспользуемся формулой бинома Ньютона:

где a и b – произвольные, а l, m – натуральные числа.
Положим

Учитывая, что в этом случае a+b=1, бином Ньютона переписывается в виде:

Далее, в последней формуле сделаем замену переменной суммирования: r = l+2. Таким образом, при начальном значении l=0 новая переменная r=2, а при конечном значении l=n-2 переменная r=n. С учетом этого, бином Ньютона окончательно преобразуется как

Приравняем теперь данную формулу и формулу (3), имеем

Очевидно, что данное равенство выполняется только в том случае, когда равны в правой и левой его частях все соответствующие слагаемые, то есть 
Таким образом, приходим к формуле для коэффициентов 
Библиография
1. Actes des notaires genoise de Pera et de Caffa de la fin de la treizieme siècle (1281-1290)/publies par Bratianu G.I. – Bucarest, 1927.– 381 P.;
2. Карпов С.П. Акты генуэзских нотариев, составленные в Каффе и других городах Причерноморья в XIV–XV вв.// Причерноморье в Средние века. – Спб., 2018.– вып. X.– 760 С.;
3. Шпирко С.В. Кого нет, того и сосчитать (или еще раз к вопросу о численности генуэзских купцов в Византии) // Историческая информатика. – 2021. – № 2. – С. 79-87;
4. Ивченко Г.И., Тимонина Е.Е. Об оценивании при выборе из конечной совокупности// Математические заметки. – 1980. – Том 28. – выпуск 4. – С. 623-633;
5. Колчин В.Ф., Севастьянов Б.А., Чистяков В.П. Случайные размещения. – М.,1976. – 225 C.;
6. Карпов С.П., Ильяшенко В.А. Опыт построения реляционной базы просопографии итальянских факторий Причерноморья (XIII—XV вв.) // Историческая информатика. – 2021. – № 3. – С. 38-48;
7. Ивченко Г.И., Медведев Ю.И. Введение в математическую статистику.– М., 2009. – 600 С.;
8. Пономарев А.Л. Кого нет, того не сосчитать? или сколько в Византии было знати и купцов// Математические модели исторических процессов. — М., 1996. — С. 236—244;
9. Пономарев А.Л. Этнический и конфессиональный состав населения Каффы в конце XIV в. по данным Массарий (о методике обработки материала)// Byzantium. Identity, Image, Influence: Extracts. XIX International Congress of Byzantine Studies. University of Copenhagen, 18-24 August, 1996: Abstracts of Communications. — Copenhagen, 1996. — P. 3116.
References
1. Actes des notaires genoise de Pera et de Caffa de la fin de la treizieme siècle (1281-1290)/publies par Bratianu G.I. – Bucarest, 1927.– 381 P.;
2. Karpov S.P. Akty genuezskih notariev, sostavlennye v Kaffe i drugih gorodah Prichernomor'ya v XIV–XV vv.// Prichernomor'e v Srednie veka. – Spb., 2018.– vyp. X.– 760 S.;
3. Shpirko S.V. Kogo net, togo i soschitat' (ili eshche raz k voprosu o chislennosti genuezskih kupcov v Vizantii) // Istoricheskaya informatika. – 2021. – № 2. – S. 79-87;
4. Ivchenko G.I., Timonina E.E. Ob ocenivanii pri vybore iz konechnoj sovokupnosti// Matematicheskie zametki. – 1980. – Tom 28. – vypusk 4. – S. 623-633;
5. Kolchin V.F., Sevast'yanov B.A., CHistyakov V.P. Sluchajnye razmeshcheniya. – M.,1976. – 225 C.;
6. Karpov S.P., Il'yashenko V.A. Opyt postroeniya relyacionnoj bazy prosopografii ital'yanskih faktorij Prichernomor'ya (XIII—XV vv.) // Istoricheskaya informatika. – 2021. – № 3. – S. 38-48;
7. Ivchenko G.I., Medvedev Yu.I. Vvedenie v matematicheskuyu statistiku.– M., 2009. – 600 S.;
8. Ponomarev A.L. Kogo net, togo ne soschitat'? ili skol'ko v Vizantii bylo znati i kupcov// Matematicheskie modeli istoricheskih processov. — M., 1996. — S. 236—244;
9. Ponomarev A.L. Etnicheskij i konfessional'nyj sostav naseleniya Kaffy v konce XIV v. po dannym Massarij (o metodike obrabotki materiala)// Byzantium. Identity, Image, Influence: Extracts. XIX International Congress of Byzantine Studies. University of Copenhagen, 18-24 August, 1996: Abstracts of Communications. — Copenhagen, 1996. — P. 3116.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Рецензия на статью «Еще раз к вопросу об оценивании численности генуэзского купечества в Византии конца XIII века с помощью методов математической статистики»
Данная статья, представленная в журнал «Историческая информатика», имеет выраженный методический характер. Она посвящена апробации одного из методов математической статистики для решения задачи отсутствующих в источниках данных о численности генуэзского купечества в Константинополе конца XIII века. Впервые эта задача была поставлена А.Л. Пономаревым, который предложил использовать данные 149 нотариальных актов, составленных в 1281 г. и опубликованных в 1927 г. Эти акты содержат имена участников коммерческих сделок, которые могли быть контрагентами, свидетелями, прочими участниками, и присутствовать неоднократно в формулярах документов. Всего в актах было идентифицировано 447 персоналий, которые были упомянуты 866 раз.
В статье на основе уже введенной в научный оборот повторной выборки и построения дискретного распределения частот встречаемости числа упоминаний одних и тех же лиц вычисляется оценка математического ожидания объема генеральной совокупности. Этот результат сопоставляется автором с ранее полученной оценкой другой статистической характеристики –моды.
Для работы с теоретически случайной выборкой автор использует метод, в котором исключаются редкие данные, соответствующие высоким частотам встречаемости (такой метод часто используется для коррекции т.н. «краевых эффектов» в распределениях гиперболического характера, таких, как закон Ципфа, использованный А.Л. Пономаревым). Правда, непонятно, почему распределение, иллюстрируемое графиком на рис. 2, автор называет равномерным (оговорка?).
Методический интерес представляет табл. 2, которая показывает влияние уровня корректировки «краевых эффектов» на объем выборки и, соответственно, на оценку неизвестного объема генеральной совокупности, что и дает автору основание сделать вывод о сближении результатов двух использованных им подходов (рис. 3). Дополнительным соображением является влияние ошибок округления, связанных с предложенными расчетами не самого объема генеральной совокупности, а обратной ей величины, дополнительным аргументом чему стали иллюстративные примеры.
Говоря о статье в целом, необходимо отметить, что в тексте не хватает содержательной компоненты: недостаточно четко сформулирована задача моделирования – оценка объема генеральной совокупности по имеющейся выборке, слишком кратким является заключение, состоящее фактически из одной фразы. На взгляд рецензента, надо больше внимания уделить сравнительному анализу методики данной статьи и упомянутой в тексте работы С.В. Шпирко «Кого нет, того и сосчитать (или еще раз к вопросу о численности генуэзских купцов в Византии)» (Историческая информатика. – 2021. – № 2), тем более, что метод, предложенный в данной статье (оценка математического ожидания), дает, по мнению самого автора, менее убедительные результаты по сравнению с предыдущей статьей, где оценивается другой статистический показатель – мода.
И, конечно, заслуживает большего внимания сравнение результатов предложенной методики с результатами известных работ А.Л. Пономарева, поскольку это может дать полезные методические рекомендации относительно выбора того или иного математического метода, к тому же на одной и той же источниковой базе. В частности, в табл. 2 мы видим достаточно большое сходство результатов автора в данной статье (660 неповторяющихся персоналий для повторной выборки объемом 600) с результатами одной из работ А.Л. Пономарева (645–650), тогда как для повторной выборки объемом в 432 автор получает по своему предыдущему методу 1558 неповторяющихся персоналий, что близко к результатам другой работы А.Л. Пономарева (1586). Думается, здесь необходима более основательная содержательная интерпретация.
В то же время статья перегружена детальными математическими расчетами, которые желательно перенести в приложение, так как она может представлять интерес только для небольшой части читателей, имеющих должную подготовку. Добавим, что для подготовленного читателя возникнут вопросы к малоинформативному рис. 1, который надо либо подробнее прокомментировать, либо совсем удалить (без ущерба для содержания).
Отметим также, что в данной статье (см. табл. 2), как и в статье, на которую ссылается автор данной, по-видимому, перепутаны ссылки на две статьи А.Л. Пономарева: в статье «Кого нет, того не сосчитать? или сколько в Византии было знати и купцов» (Математические модели исторических процессов. – М., 1996), у А.Л. Пономарева нет той оценки объема генеральной совокупности (645–650), которую приводит автор, видимо, эта оценка дается в работе «Численность купечества и объем торговли генуэзской колонии в Пере в 1281 г. (по данным картулярия Габриэле де Предоно)» (XVIII Международный конгресс византинистов. Резюме сообщений. Московский государственный университет им. М.В. Ломоносова 8-15 августа 1991 г.– М., 1991). В библиографию желательно внести и публикацию: Карпов С.П., Ильяшенко В.А. Опыт построения реляционной базы просопографии итальянских факторий Причерноморья (XIII – XV вв.) // Историческая информатика. – 2021. – №3.
Автору следует также более внимательно отнестись к оформлению работы. Во-первых, библиографический список необходимо привести в соответствие с ГОСТом, особенно по части предписанных знаков пунктуации и пробелов. Во-вторых, формулы не всегда удачно «встроены» в текст, а располагаются выше строки. В-третьих, в структуре работы два раздела (Численное моделирование и Задача оценивания) имеют один и тот же номер – II.
Наконец, необходимо проверить орфографию: например, исправить раздельное написание (не трудно, не устойчиво) на слитное.
Тем не менее, в методическом плане статья представляет интерес для авторов, занимающихся квантитативной историей, и может быть рекомендована к печати с учетом сделанных замечаний.
Замечания главного редактора от 01.02.2022: "Автор в полной мере учел замечания рецензентов и исправил статью. Доработанная статья рекомендуется к публикации"
|
 Рус
Рус










