|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Зорченков А.М.
Автоматизация миграций сторонних библиотек
// Программные системы и вычислительные методы.
2022. № 1.
С. 71-87.
DOI: 10.7256/2454-0714.2022.1.34337 URL: https://nbpublish.com/library_read_article.php?id=34337
Автоматизация миграций сторонних библиотек
Зорченков Алексей Михайлович
Ведущий инженер, ООО “Техкомпания Хуавэй”
141002, Россия, Московская область, г. Мытищи, ул. Белобородова, 15, кв. 81
Zorchenkov Alexey Mikhailovich
Leading Engineer, Huawei Tech Company LLC
141002, Russia, Moskovskaya oblast', g. Mytishchi, ul. Beloborodova, 15, kv. 81

|
zorchenkov@gmail.com
|
|
 |
|
DOI: 10.7256/2454-0714.2022.1.34337
Дата направления статьи в редакцию:
16-11-2020
Дата публикации:
03-04-2022
Аннотация:
Миграция вручную между различными сторонними библиотеками представляет собой проблему для разработчиков программного обеспечения. Разработчикам обычно необходимо изучить интерфейсы прикладного программирования обеих библиотек, а также прочитать их документацию, чтобы найти подходящие сопоставления между заменяющим и заменяемым методами. В этой статье я представлю новый подход (MIG) к машинному обучению, который рекомендует сопоставления между методами двух API библиотек. Моя модель учится на вручную найденных данных реализованных миграций, извлекает набор функций, связанных с подобием сигнатуры метода и текстовой документации. Я оценил модель с использованием 8 популярных миграций, собранных из 57 447 проектов Java с открытым исходным кодом. Результаты показывают, что модель может рекомендовать соответствующие сопоставления API библиотеки со средним показатель точности 87%. В данном исследовании рассматривается проблема рекомендации сопоставления методов при миграции между сторонними библиотеками. Описан новый подход, рекомендующий сопоставление методов между двумя неизвестными библиотеками с использованием признаков, извлеченных из лексического сходства между именами методов и текстовым подобием документаций методов. Я оценил результат, проверяя, как данный подход и три других наиболее часто используемых подходов рекомендуют сопоставление методов миграции для 8 популярных библиотек. Я показал, что предлагаемый подход показывает гораздо лучшую точность и производительность, чем другие 3 метода. Качественный и количественный анализ результатов показывает увеличение точности на 39.51% в сравнении с другими широко известными подходами.
Ключевые слова:
миграции библиотек, машинное обучение, Обработка естественного языка, Частота термина, метод опорных векторов, Обратная частота документа, инженерия признаков, Документация библиотек, извлечение информации, модель векторного простанства
Abstract: Manual migration between various third-party libraries is a problem for software developers. Developers usually need to study the application programming interfaces of both libraries, as well as read their documentation to find suitable comparisons between the replacement and the replaced methods. In this article, I will present a new approach (MIG) to machine learning that recommends mappings between the methods of two API libraries. My model learns from manually found data of implemented migrations, extracts a set of functions related to the similarity of the method signature and text documentation. I evaluated the model using 8 popular migrations compiled from 57,447 open source Java projects. The results show that the model can recommend appropriate library API mappings with an average accuracy rate of 87%. This study examines the problem of recommending method comparisons when migrating between third-party libraries. A new approach is described that recommends the comparison of methods between two unknown libraries using features extracted from the lexical similarity between method names and textual similarity of method documentation. I evaluated the result by checking how this approach and three other most commonly used approaches recommend a comparison of migration methods for 8 popular libraries. I have shown that the proposed approach shows much better accuracy and performance than the other 3 methods. Qualitative and quantitative analysis of the results shows an increase in accuracy by 39.51% in comparison with other well-known approaches.
Keywords: library migrations, machine learning, Natural Language Processing, Frequency of the term, the method of support vectors, Reverse document frequency, feature engineering, Library documentation, extracting information, vector space model
Принятые сокращения:
|
Аббревиатура
|
Полное имя
|
Описание
|
|
NLP
|
Natural Language Processing
|
Обработка естественного языка
|
|
TF-IDF
|
Term Frequency -Inverse Document Frequency
|
Статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Вес некоторого слова пропорционален частоте употребления этого слова в документе и обратно пропорционален частоте употребления слова во всех документах коллекции.
|
|
SVM
|
Support Vector Machine
|
метод опорных векторов
|
1 Введение
Современные программные системы сильно зависят от сторонних библиотек для экономии времени, сокращения затрат на внедрение и повышения качества программного обеспечения, предлагая обширную, надежную и современную функциональность [1],[2],[3]. Однако поскольку программные системы быстро развиваются, существует потребность в соответствующих инструментах, предоставляющих надежные и эффективные методы разработчикам в принятии решений при замене старых и устаревших библиотек на современные. Этот процесс замены библиотеки на другой, при сохранении того же поведения кода, известен как миграция библиотек [4],[5]. Широко известно, что процесс миграции между библиотеками является довольно трудным, подверженным ошибкам и трудоемким процессом [6],[2],[3],[1]. Разработчикам необходимо изучить API новой библиотеки и связанную с ней документацию, чтобы найти правильный метод (-ы) API для замены соответствующей функциональности в текущей реализации, принадлежащую API устаревшей библиотеки. Разработчикам нужно часто тратить значительное время, чтобы убедиться, что новые функции не имеют никакого побочного эффекта. Например, предыдущие работы показали, что разработчики обычно тратят до 42 дней на миграцию между библиотеками [7].
Обычно компании-разработчики программного обеспечения назначают задачи миграции разработчикам, у которых есть больше опыта в целях снижения рисков возникновения побочных неблагоприятных эффектов в продукте. Например, на [Рисунок 1] показано, что разработчики, у которых больше десяти лет опыта работы,
Рисунок 1
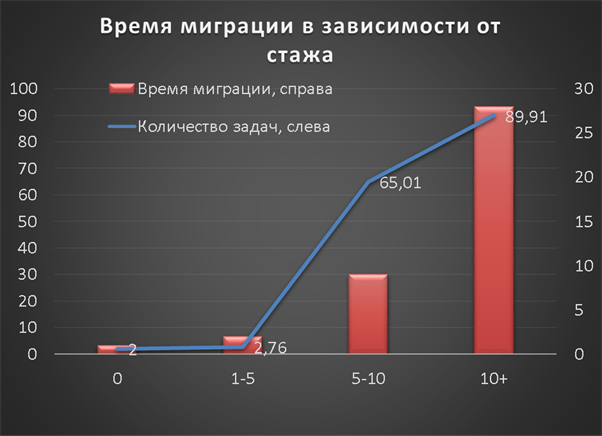
выполняют миграции чаще, чем разработчики с более меньшим стажем. Данные основаны на миграциях, собранных Alrubaye et al. [6], содержащих информацию о разработчиках, которые ранее выполняли задачи миграции, такую как, имена, адреса электронной почты, годы опыта и даты миграции. Кроме того, я обнаружил, что 95,3% из 57 447 проектов Java использовали хотя бы одну стороннюю библиотеку (API). В среднем насчитывается 65 процессов обновления или миграции API для каждого проекта. Ранее было предложено ряд подходов и методов миграции с целью определения замены устаревшего API на более новую версию того же API [8],[9],[10],[11].
Другие исследования рекомендуют, какую библиотеку выбрать при замене: [12],[13],[14],[15],[16]. Однако такие подходы не дают четкого руководства разработчикам как конкретно выполнить гибко настраиваемую миграцию на уровне методов. В действительности, рекомендации на уровне методов были в центре внимания многих исследований, но только чтобы рекомендовать одну и ту же библиотеку на разных языках программирования и операционных системах. [17],[18],[19].
Очевидно, что существует потребность в более комплексной методике рекомендаций, которая не зависит ни от библиотеки ни от языка программирования, т.е. принимает в качестве входных данных две разные библиотеки и показывает, как заменить одну на другую на уровне методов.
В этой статье я представляю новый метод машинного обучения - модель, обучаемая на ранее выполненных разработчиками миграциях и рекомендует миграции на уровне API для аналогичных контекстов миграции. Модель принимает на входе две разные библиотеки и выдает в качестве результата потенциальные сопоставления между их методами API. Основная идея заключается в повторном использовании ценных знаний по миграциям, доступных в предыдущих миграциях, выполненных разработчиками вручную в других проектах с открытым исходным кодом, т. е. учиться у «Мудрости толпы». Модель использует предопределенные особенности, связанные с подобием сигнатур методов и их соответствующую документацию API для построения алгоритма.
2 Методология Правило миграции обозначается парой: исходной (удаленной) библиотеки 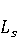 и целевой (добавленной) библиотекой и целевой (добавленной) библиотекой 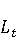 и представляется в виде и представляется в виде 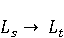 . Например, . Например, 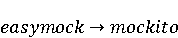 представляет Правило Миграции где библиотека easymock мигрирует в новую библиотеку mockito. Для заданного правила миграции обозначим представляет Правило Миграции где библиотека easymock мигрирует в новую библиотеку mockito. Для заданного правила миграции обозначим 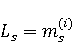 – набор методов, принадлежащих , где – набор методов, принадлежащих , где 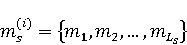 , а , а 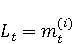 – набор методов, принадлежащих , где – набор методов, принадлежащих , где 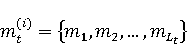 . Нашей целью является найти соответствия между и . Нашей целью является найти соответствия между и 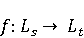 .таким образом, что каждый исходный метод .таким образом, что каждый исходный метод 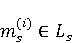 отобразится на соответствующий целевой метод отобразится на соответствующий целевой метод 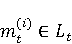 , этот процесс называется отображением методов , этот процесс называется отображением методов
Рисунок 2: Подход к рекомендации отображения методов
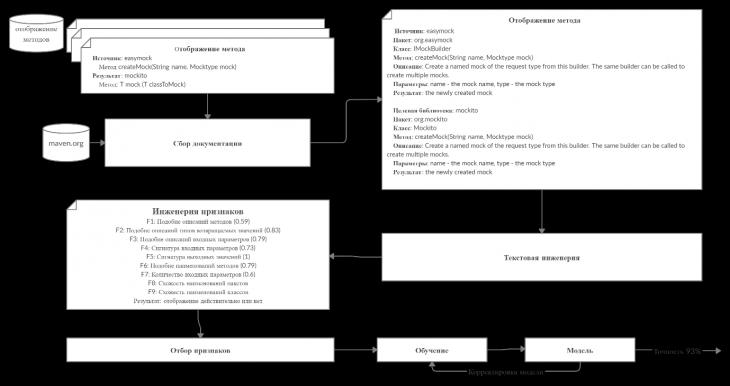 На [Рисунок 2] представлен полный процесс, состоящий из двух фаз: первая фаза, называемая фазой сборки, собирает информацию, например документацию по библиотекам, чтобы сформировать свойства. Эта фаза начинается с (А) сбора API и их документации, (B) предварительной обработки текста и (C) инженерии признаков для получения набора признаков из сигнатур методов и документации API. Вторая фаза, фаза рекомендации, начинается с отбора значащих признаков перед тем как отправить их в процедуру обучения. Процедура обучения создает модель, используемую для рекомендаций отображений между двумя библиотеками. 2.1 Сбор информации Эта фаза получает на входе два параметра. Один - набор отображений методов, состоящий из отобранных вручную корректных и некорректных отображений методов для различных правил миграций [6]. Например на [Рисунок 2] для данного правила миграции На [Рисунок 2] представлен полный процесс, состоящий из двух фаз: первая фаза, называемая фазой сборки, собирает информацию, например документацию по библиотекам, чтобы сформировать свойства. Эта фаза начинается с (А) сбора API и их документации, (B) предварительной обработки текста и (C) инженерии признаков для получения набора признаков из сигнатур методов и документации API. Вторая фаза, фаза рекомендации, начинается с отбора значащих признаков перед тем как отправить их в процедуру обучения. Процедура обучения создает модель, используемую для рекомендаций отображений между двумя библиотеками. 2.1 Сбор информации Эта фаза получает на входе два параметра. Один - набор отображений методов, состоящий из отобранных вручную корректных и некорректных отображений методов для различных правил миграций [6]. Например на [Рисунок 2] для данного правила миграции 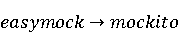 мы определяем одно из корректных отображений между следующими методами: мы определяем одно из корректных отображений между следующими методами: 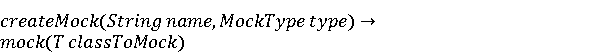 . Второй вход этой фазы – документация API, собранная Сборщиком Документации [Рисунок 2]. Для каждого из отображений методов Сборщик Документации собирает документацию API для исходного и целевого методов. В соответствии с правилом миграции Сборщик автоматически скачивает документацию по библиотеке в jar формате с Maven Central Repository. Далее Сборщик конвертирует API документацию из jar файла во множество исходных файлов HTML используя doclet API, анализирует все HTML файлы и выбирает документацию по описаниям классов, методов, входным параметрам, выходным параметров, наименованиям пакетов, наименованиям классов. Сборщик Документации соотносит документацию с каждым из отображений методов. Процесс сбора заканчивается только когда собрана вся информация по каждому из методов, участвующих в отображениях. 2.2 Текстовая инженерия Предлагаемый подход имеет целью рекомендовать соответствия методов API в автоматическом режиме помогая разработчикам при выполнении задач миграций библиотек. Задача миграции обычно состоит из анализа структурированных и неструктурированных источников данных, включая сигнатуры методов, текстовые описания API, примеры фрагментов кода из открытых репозиториев и т. д. Для автоматического изучения таких данных я использую методы информационного поиска (IR), такие как предварительную обработку текста, модель векторного пространства и косинусное подобие для предварительной обработки данных из источников. 2.3 Извлечение информации (IE) Пусть . Второй вход этой фазы – документация API, собранная Сборщиком Документации [Рисунок 2]. Для каждого из отображений методов Сборщик Документации собирает документацию API для исходного и целевого методов. В соответствии с правилом миграции Сборщик автоматически скачивает документацию по библиотеке в jar формате с Maven Central Repository. Далее Сборщик конвертирует API документацию из jar файла во множество исходных файлов HTML используя doclet API, анализирует все HTML файлы и выбирает документацию по описаниям классов, методов, входным параметрам, выходным параметров, наименованиям пакетов, наименованиям классов. Сборщик Документации соотносит документацию с каждым из отображений методов. Процесс сбора заканчивается только когда собрана вся информация по каждому из методов, участвующих в отображениях. 2.2 Текстовая инженерия Предлагаемый подход имеет целью рекомендовать соответствия методов API в автоматическом режиме помогая разработчикам при выполнении задач миграций библиотек. Задача миграции обычно состоит из анализа структурированных и неструктурированных источников данных, включая сигнатуры методов, текстовые описания API, примеры фрагментов кода из открытых репозиториев и т. д. Для автоматического изучения таких данных я использую методы информационного поиска (IR), такие как предварительную обработку текста, модель векторного пространства и косинусное подобие для предварительной обработки данных из источников. 2.3 Извлечение информации (IE) Пусть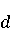 – сигнатура метода (наименование, имя класса или пакета). На этом этапе я извлекаю – сигнатура метода (наименование, имя класса или пакета). На этом этапе я извлекаю 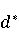 используя функцию используя функцию  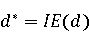 . Например, если – это наименование целевого пакета, то генерируется . Например, если – это наименование целевого пакета, то генерируется  следующим образом: следующим образом: 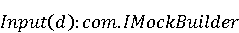 1 – Убираем специальные символы: заменяем все специальные символы, такие как точки на пробелы, таком образом на выходе этого шага получаем 1 – Убираем специальные символы: заменяем все специальные символы, такие как точки на пробелы, таком образом на выходе этого шага получаем 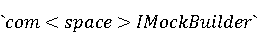 2. – Разбивка с помощью нотации CamelCase: разбиваем все идентификаторы с использованием CamelCase нотации, выходом на данном шаге будет 2. – Разбивка с помощью нотации CamelCase: разбиваем все идентификаторы с использованием CamelCase нотации, выходом на данном шаге будет 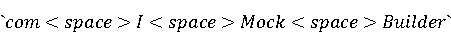 . . 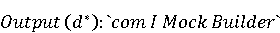 2.4 Подготовка текстовых данных может содержать смесь слов и специальных символов, таких как точка, двоеточие и т. д. В данный процесс очищает документы от специальных символов и общеупотребительных английских слов, таких как «the» и «is». Затем применяется «корневое» преобразование ко всем извлеченным словам, чтобы поместить их в их корневой формат с использованием NLP. Этот процесс снижает уровень «шума» при вычислении подобия между двумя документами. 2.4 Подготовка текстовых данных может содержать смесь слов и специальных символов, таких как точка, двоеточие и т. д. В данный процесс очищает документы от специальных символов и общеупотребительных английских слов, таких как «the» и «is». Затем применяется «корневое» преобразование ко всем извлеченным словам, чтобы поместить их в их корневой формат с использованием NLP. Этот процесс снижает уровень «шума» при вычислении подобия между двумя документами.  . Например, если является описанием исходного метода, то . Например, если является описанием исходного метода, то 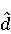 создается следующим образом: создается следующим образом:  `Create a named mock of the request type from this builder.The same builder can be called to create multiple mocks.` 1 – Токенизация: Разбиваем весь текст на отдельные слова: [’Create’, ’a’, ’named’, ’mock’, ’of’, ’the’, ’request’, ’type’, ’from’, ’this’, ’builder’, ’.’, ’The’, ’same’, ’builder’, ’can’, ’be’, ’called’, ’to’, ’create’, ’multiple’, ’mocks’, ’.’] 2. – Убираем ненужную пунктуацию: такие теги как «.» удаляются из массива токенов, получаем: [’Create’, ’a’, ’named’, ’mock’, ’of’, ’the’, ’request’, ’type’, ’from’, ’this’, ’builder’, ’The’, ’same’, ’builder’, ’can’, ’be’, ’called’, ’to’, ’create’, ’multiple’, ’mocks’] 3. Удаляем английские зарезервированные и стоп слова, такие как ”a”, ”of”, ”the”, ”from”, ”this”, ”can”, ”be”, ”to”: [’Create’, ’named’, ’mock’, ’request’, ’type’, ’builder’, ’builder’, ’called’, ’create’, ’multiple’, ’mocks’] 4. Лемматизация: процесс преобразования слов к их корням, например `Create a named mock of the request type from this builder.The same builder can be called to create multiple mocks.` 1 – Токенизация: Разбиваем весь текст на отдельные слова: [’Create’, ’a’, ’named’, ’mock’, ’of’, ’the’, ’request’, ’type’, ’from’, ’this’, ’builder’, ’.’, ’The’, ’same’, ’builder’, ’can’, ’be’, ’called’, ’to’, ’create’, ’multiple’, ’mocks’, ’.’] 2. – Убираем ненужную пунктуацию: такие теги как «.» удаляются из массива токенов, получаем: [’Create’, ’a’, ’named’, ’mock’, ’of’, ’the’, ’request’, ’type’, ’from’, ’this’, ’builder’, ’The’, ’same’, ’builder’, ’can’, ’be’, ’called’, ’to’, ’create’, ’multiple’, ’mocks’] 3. Удаляем английские зарезервированные и стоп слова, такие как ”a”, ”of”, ”the”, ”from”, ”this”, ”can”, ”be”, ”to”: [’Create’, ’named’, ’mock’, ’request’, ’type’, ’builder’, ’builder’, ’called’, ’create’, ’multiple’, ’mocks’] 4. Лемматизация: процесс преобразования слов к их корням, например  . [’Create’, ’name’, ’mock’, ’request’, ’type’, ’builder’, ’builder’, ’call’, ’create’, ’multiple’, ’mock’] 5. . [’Create’, ’name’, ’mock’, ’request’, ’type’, ’builder’, ’builder’, ’call’, ’create’, ’multiple’, ’mock’] 5.  - последний шаг, на котором все символы преобразуются к нижнему регистру и все токены собираются в единую строку `create mock request type builder builder create multiple mock` 2.5 Представление в виде векторного пространства. Как часть процесса генерации признаков я рассчитываю подобие между документациями исходного метода - последний шаг, на котором все символы преобразуются к нижнему регистру и все токены собираются в единую строку `create mock request type builder builder create multiple mock` 2.5 Представление в виде векторного пространства. Как часть процесса генерации признаков я рассчитываю подобие между документациями исходного метода 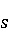 и целевого и целевого 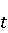 , что включает подобие описаний обоих методов, наименований методов или описаний типа возвращаемых значений и . Для вычисления подобия между двумя текстовыми документами необходимо сконвертировать текст в числовой вектор, а затем рассчитать их близость через косинусное подобие. Для конвертации текстов в числовые вектора я использую технологию TF-IDF. Далее для нахождения подобия между векторами я использую косинусное подобие [25]: , что включает подобие описаний обоих методов, наименований методов или описаний типа возвращаемых значений и . Для вычисления подобия между двумя текстовыми документами необходимо сконвертировать текст в числовой вектор, а затем рассчитать их близость через косинусное подобие. Для конвертации текстов в числовые вектора я использую технологию TF-IDF. Далее для нахождения подобия между векторами я использую косинусное подобие [25]: 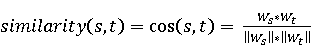 , где , где 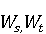 – исходный и целевой вектора. 2.6 Инженерия признаков. Модели машинного обучения требуется набор признаков для обработки. В этом процессе я получаю числовые признаки из имеющейся информации по исходному и целевому методам, позволяющие модели рекомендовать более точные результаты соответствий методов. Изначально я извлекаю 9 различных признаков – исходный и целевой вектора. 2.6 Инженерия признаков. Модели машинного обучения требуется набор признаков для обработки. В этом процессе я получаю числовые признаки из имеющейся информации по исходному и целевому методам, позволяющие модели рекомендовать более точные результаты соответствий методов. Изначально я извлекаю 9 различных признаков 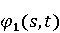 .. ..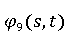 из информации по методам и и один бинарный класс из информации по методам и и один бинарный класс  , который либо действителен либо нет и преопределен в наборе данных. Каждый признак рассчитывается для каждого метода из исходной библиотеки , который либо действителен либо нет и преопределен в наборе данных. Каждый признак рассчитывается для каждого метода из исходной библиотеки 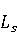 с каждым методом целевой библиотеки с каждым методом целевой библиотеки 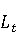 . · Описание методов . · Описание методов 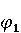 : я извлекаю путем расчета косинусного подобия между описанием исходного метода : я извлекаю путем расчета косинусного подобия между описанием исходного метода 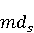 и описанием целевого метода и описанием целевого метода 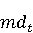 . В данном случае я не применяю . В данном случае я не применяю 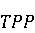 на описание метода поскольку оно может содержать примеры программного кода, которые будут очищены в случае применения . Было проверено, что добавление этих примеров программного кода увеличивает точность рекомендаций замены методов на 3% по сравнению с отбрасыванием этих примеров. Например, расчет косинусного подобия между `Create a named mock of the request type from this builder. The same builder can be called to create multiple mocks` и `Creates mock object of given class or interface. See examples in Javadoc for Mockito class` дает результатом 0.59. · Описание типа возвращаемого значения на описание метода поскольку оно может содержать примеры программного кода, которые будут очищены в случае применения . Было проверено, что добавление этих примеров программного кода увеличивает точность рекомендаций замены методов на 3% по сравнению с отбрасыванием этих примеров. Например, расчет косинусного подобия между `Create a named mock of the request type from this builder. The same builder can be called to create multiple mocks` и `Creates mock object of given class or interface. See examples in Javadoc for Mockito class` дает результатом 0.59. · Описание типа возвращаемого значения 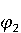 : этот признак извлекается путем применения к описанию типа возвращаемого значения исходным методом : этот признак извлекается путем применения к описанию типа возвращаемого значения исходным методом 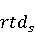 и целевым и целевым 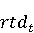 , получения соответственно , получения соответственно 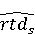 и и 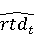 и далее расчета косинусного подобия между и . Например, расчет косинусного подобия между `the newly created mock ` и ` mock object` дает результатом 0.83. · Описание входных параметров и далее расчета косинусного подобия между и . Например, расчет косинусного подобия между `the newly created mock ` и ` mock object` дает результатом 0.83. · Описание входных параметров 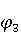 : этот признак извлекается путем применения к описанию типа входных параметров исходного метода : этот признак извлекается путем применения к описанию типа входных параметров исходного метода 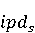 и целевого и целевого 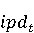 , получения соответственно , получения соответственно 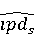 и и 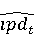 и далее расчета косинусного подобия между и . Например, расчет косинусного подобия между ` name -the mock name — type - the mock type` и `classToMock - class or interface to mock` дает результатом 0.79. · Сигнатура входных параметров и далее расчета косинусного подобия между и . Например, расчет косинусного подобия между ` name -the mock name — type - the mock type` и `classToMock - class or interface to mock` дает результатом 0.79. · Сигнатура входных параметров 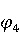 :этот признак извлекается путем применения к сигнатуре входных параметров исходного метода :этот признак извлекается путем применения к сигнатуре входных параметров исходного метода 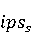 и целевого и целевого 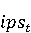 , получения соответственно , получения соответственно 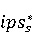 и и 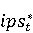 и далее расчета косинусного подобия между и . Например, применяя к `String name, MockType type` и `T classToMock` и рассчитывая косинусное подобие между и дает результатом 0.73. · Сигнатура типов выходных параметров и далее расчета косинусного подобия между и . Например, применяя к `String name, MockType type` и `T classToMock` и рассчитывая косинусное подобие между и дает результатом 0.73. · Сигнатура типов выходных параметров 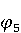 :этот признак извлекается путем сравнения сигнатуры типа возвращаемого значения исходного метода :этот признак извлекается путем сравнения сигнатуры типа возвращаемого значения исходного метода 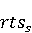 и целевого и целевого 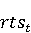 . В случае если типы совпадают, на выходе имеем 1, иначе 0. Например, если оба и возвращают обобщенный тип . В случае если типы совпадают, на выходе имеем 1, иначе 0. Например, если оба и возвращают обобщенный тип 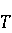 , результатом имеем 1. · Наименование методов , результатом имеем 1. · Наименование методов 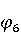 :этот признак извлекается путем применения к наименованию исходного метода :этот признак извлекается путем применения к наименованию исходного метода 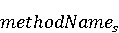 и целевого и целевого 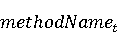 , получения соответственно , получения соответственно 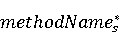 и и 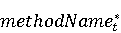 и далее расчета косинусного подобия между и . Например, применяя к `createMock ` и `mock` и рассчитывая косинусное подобие между и дает результатом 0.79. · Количество входных параметров и далее расчета косинусного подобия между и . Например, применяя к `createMock ` и `mock` и рассчитывая косинусное подобие между и дает результатом 0.79. · Количество входных параметров 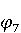 :этот признак извлекается путем подсчета соотношения между количеством входных параметров исходного метода :этот признак извлекается путем подсчета соотношения между количеством входных параметров исходного метода 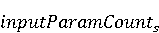 и целевого и целевого 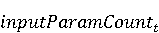 : : 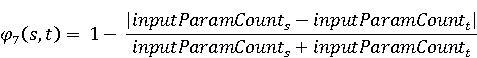 Например, на Рисунок 2 Например, на Рисунок 2 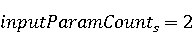 (name, type) и (name, type) и 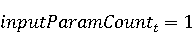 (classToMock) что дает результатом 0.6. · Наименование пакетов (classToMock) что дает результатом 0.6. · Наименование пакетов 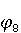 :этот признак извлекается путем применения к наименованию пакета исходного метода :этот признак извлекается путем применения к наименованию пакета исходного метода 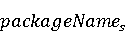 и целевого и целевого 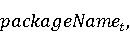 получения соответственно получения соответственно 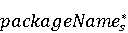 и и 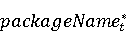 и далее расчета косинусного подобия между и . Например, применяя к `org.easymock` и и далее расчета косинусного подобия между и . Например, применяя к `org.easymock` и 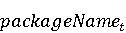 `org.mockito` и рассчитывая косинусное подобие между и дает результатом 0.96. · Наименование пакетов `org.mockito` и рассчитывая косинусное подобие между и дает результатом 0.96. · Наименование пакетов 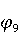 :этот признак извлекается путем применения к наименованию класса, куда входит исходный метод :этот признак извлекается путем применения к наименованию класса, куда входит исходный метод 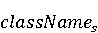 и целевого и целевого 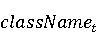 , получения соответственно , получения соответственно 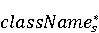 и и 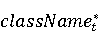 и далее расчета косинусного подобия между и . Например, применяя к `IMockBuilder` и `Mockito` и рассчитывая косинусное подобие между и дает результатом 0.94. 2.7 Отбор признаков. Несмотря на то, что уже определен набор признаков и далее расчета косинусного подобия между и . Например, применяя к `IMockBuilder` и `Mockito` и рассчитывая косинусное подобие между и дает результатом 0.94. 2.7 Отбор признаков. Несмотря на то, что уже определен набор признаков 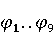 , нет полной уверенности, что эти признаки будут достаточны модели машинного обучения для рекомендаций замены соответствующих API методов. Для наглядности представления вклада каждого из признаков в конечный результат я применил Фильтр Отбора Признаков [26]. Данный фильтр показал, что не имеет значительного вклада для рекомендации имени класса. Таким образом, был убран из расчетов. 2.8 Обучение. Существует несколько алгоритмов машинного обучения разработанных для рассматриваемого случая. Данные алгоритмы принимают вид классификатора, работающего над экземплярами объектов. В моем случае экземплярами объектов являются вектора признаков, полученных из исходного и целевого методов: до . На фазе обучения я подаю на вход классификатора набор объектов с размеченным результатом. Разметка является бинарным значением, классифицирующем отображение метода как «корректное» или «некорректное». Все объекты нормализованы с помощью z-score для избежания проблемы переобучения. По завершению процесса обучения классификатор генерирует модель. Далее на вход модели подается экземпляр, не участвовавший в процессе обучения, и модель выдает на выходе вероятности принадлежности к корректному или некорректному классу отображения метода. Был проведен тщательный сравнительный анализ различных классификаторов, которые могут быть кандидатами на использование в качестве базовой модели. Расссчитывалась точность рекомендаций по формуле: , нет полной уверенности, что эти признаки будут достаточны модели машинного обучения для рекомендаций замены соответствующих API методов. Для наглядности представления вклада каждого из признаков в конечный результат я применил Фильтр Отбора Признаков [26]. Данный фильтр показал, что не имеет значительного вклада для рекомендации имени класса. Таким образом, был убран из расчетов. 2.8 Обучение. Существует несколько алгоритмов машинного обучения разработанных для рассматриваемого случая. Данные алгоритмы принимают вид классификатора, работающего над экземплярами объектов. В моем случае экземплярами объектов являются вектора признаков, полученных из исходного и целевого методов: до . На фазе обучения я подаю на вход классификатора набор объектов с размеченным результатом. Разметка является бинарным значением, классифицирующем отображение метода как «корректное» или «некорректное». Все объекты нормализованы с помощью z-score для избежания проблемы переобучения. По завершению процесса обучения классификатор генерирует модель. Далее на вход модели подается экземпляр, не участвовавший в процессе обучения, и модель выдает на выходе вероятности принадлежности к корректному или некорректному классу отображения метода. Был проведен тщательный сравнительный анализ различных классификаторов, которые могут быть кандидатами на использование в качестве базовой модели. Расссчитывалась точность рекомендаций по формуле: 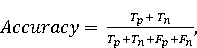 где где 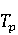 - количество всех верных отображений методов, которые были рекомендованы корректно. - количество всех верных отображений методов, которые были рекомендованы корректно. 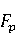 – количество всех неправильных отображений, рекомендованных как корректные. – количество всех неправильных отображений, рекомендованных как корректные. 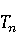 – количество всех неверных отображений, которые модель выдавала как неверные. – количество всех неверных отображений, которые модель выдавала как неверные. 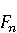 – количество корректных отображений, рекомендованных моделями как неверные. Чем больше – количество корректных отображений, рекомендованных моделями как неверные. Чем больше 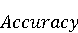 , тем лучше модель. Ошибка модели измерялась по формуле: , тем лучше модель. Ошибка модели измерялась по формуле: 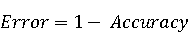 . Чем меньше ошибка, тем лучше модель. Ensemble Learning: случайным образом выбирает образцы из набора данных и для каждой выборки он применяет Дерево Решений для построения и проверки обучения используя оставшуюся часть набора данных. Затем он использует неверно предсказанные образцы как часть обучающего набора данных, используемые последующим обучением. Таким образом он находит вероятности результатов всех обучений, что повышает точность обучения и уменьшает проблему переобучения. Последовательная настройка параметров обучения показала, что данные по 233 примерам дают наименьшую ошибку, что означает, что мы имеем 233 возможных разных решений. Как показано на [Рисунок 3] сравнивались самые передовые модели обучения: нейронные сети, SVM, случайный лес, усиленные деревья решений. . Чем меньше ошибка, тем лучше модель. Ensemble Learning: случайным образом выбирает образцы из набора данных и для каждой выборки он применяет Дерево Решений для построения и проверки обучения используя оставшуюся часть набора данных. Затем он использует неверно предсказанные образцы как часть обучающего набора данных, используемые последующим обучением. Таким образом он находит вероятности результатов всех обучений, что повышает точность обучения и уменьшает проблему переобучения. Последовательная настройка параметров обучения показала, что данные по 233 примерам дают наименьшую ошибку, что означает, что мы имеем 233 возможных разных решений. Как показано на [Рисунок 3] сравнивались самые передовые модели обучения: нейронные сети, SVM, случайный лес, усиленные деревья решений.
Рисунок 3
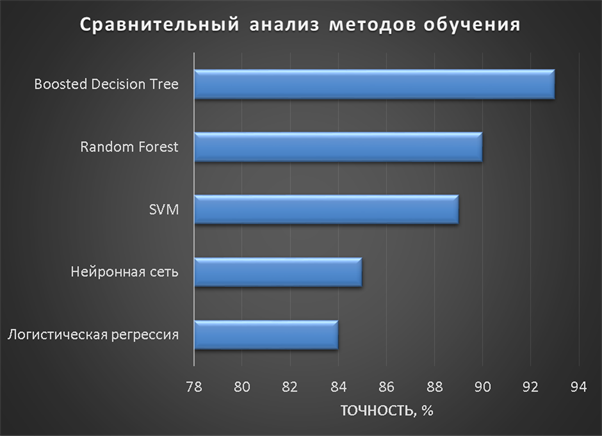
Методы, требующие значительное количество данных на этапах обучения и проверки (логистическая регрессия и нейронные сети) показали наихудшую точность. Напротив, усиленные деревья решений известны отличной производительностью на относительно небольших наборах данных в силу использования набора Деревьев Решений и механизма взвешенного выбора.
Рисунок 4
2.9 Настройка параметров.
Рисунок 5
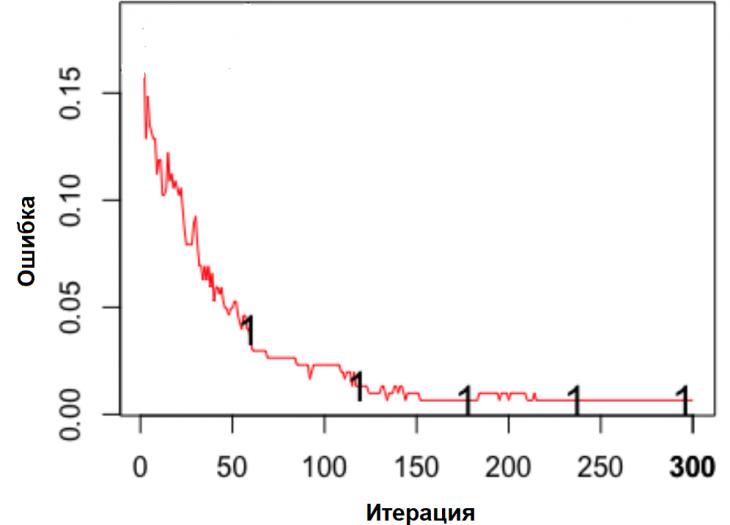
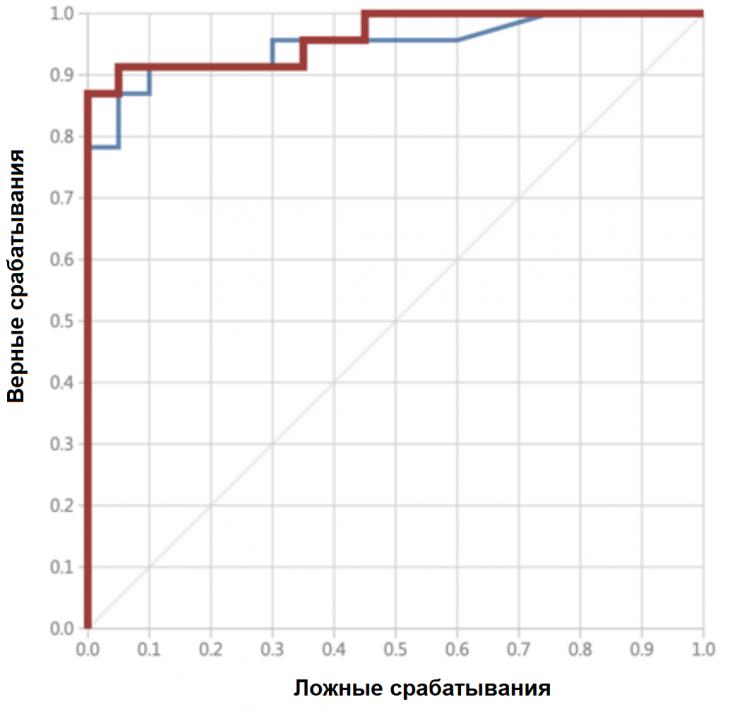 Настройка параметров значительно влияет на обучение в заданной задаче [30]. В связи с этим я произвел настройку обучения для улучшения точности. Поскольку используется обучение на базе Двух классового усиленного дерева принятия решений, я начал настройку со следующих параметров: максимальное количество листьев 20, минимальное количество экземпляров листьев 10, скорость обучения 0.2, количество деревьев 100. Далее параметры обучения последовательно изменялись до тех пор, пока ошибка не стабилизировалась на уровне 0.5% [Рисунок 4] при количестве листьев 6, минимальном количестве экземпляров листьев 47, скорости обучения 0.14, количестве деревьев 233. На [Рисунок 5] представлено сравнение обучения с и без настройки параметров. График обучения с настройкой параметров расположен дальше от кривой и точность увеличивается на 2.3%: с 90.7% до 93.0% 3 Известные методы рекомендаций отображений методов миграций API библиотек 3.1 Рассматриваемые подходы. Рассмотрим реализацию три других самых лучших подхода для сравнения с MIG. · Обучение ранжированию (Learning to Rank, LTR). Используем тот же набор признаков Настройка параметров значительно влияет на обучение в заданной задаче [30]. В связи с этим я произвел настройку обучения для улучшения точности. Поскольку используется обучение на базе Двух классового усиленного дерева принятия решений, я начал настройку со следующих параметров: максимальное количество листьев 20, минимальное количество экземпляров листьев 10, скорость обучения 0.2, количество деревьев 100. Далее параметры обучения последовательно изменялись до тех пор, пока ошибка не стабилизировалась на уровне 0.5% [Рисунок 4] при количестве листьев 6, минимальном количестве экземпляров листьев 47, скорости обучения 0.14, количестве деревьев 233. На [Рисунок 5] представлено сравнение обучения с и без настройки параметров. График обучения с настройкой параметров расположен дальше от кривой и точность увеличивается на 2.3%: с 90.7% до 93.0% 3 Известные методы рекомендаций отображений методов миграций API библиотек 3.1 Рассматриваемые подходы. Рассмотрим реализацию три других самых лучших подхода для сравнения с MIG. · Обучение ранжированию (Learning to Rank, LTR). Используем тот же набор признаков 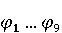 , и тот же набор данных, оцениваем каждую пару методов, принадлежащих исходному и целевому API. Функция оценки – это линейная комбинация признаков, чьи веса обучены на известных сопоставлениях методов миграций. , и тот же набор данных, оцениваем каждую пару методов, принадлежащих исходному и целевому API. Функция оценки – это линейная комбинация признаков, чьи веса обучены на известных сопоставлениях методов миграций. 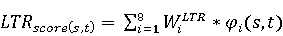 , где , где 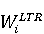 - результат обучения на ранее размеченных соответствиях методов. Для справедливости сравнения LTR с другими алгоритмами, принимается в расчет только метод, получивший максимальную оценку. · Подход на основе интеллектуального анализа текста (text mining based approach, TMAP). TMAP [19] метод ранжирует соответствия методов на основе пяти признаков: - результат обучения на ранее размеченных соответствиях методов. Для справедливости сравнения LTR с другими алгоритмами, принимается в расчет только метод, получивший максимальную оценку. · Подход на основе интеллектуального анализа текста (text mining based approach, TMAP). TMAP [19] метод ранжирует соответствия методов на основе пяти признаков: 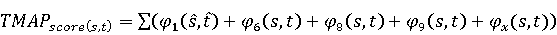 , где , где 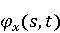 получена путем применени к описанию класса исходного метода получена путем применени к описанию класса исходного метода 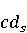 и целевого и целевого 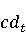 , создающего , создающего 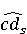 и и 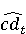 , далее применяется косинусное подобие к и . , далее применяется косинусное подобие к и . 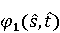 получена путем применения к описаниям исходного метода и целевого , созданию получена путем применения к описаниям исходного метода и целевого , созданию 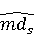 и и 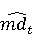 и расчета косинусного подобия между и . · Сигнатура метода (Method Signature, MS). Этот метод рассчитывает подобие сигнатур методов для всех возможных комбинаций следующим образом [28]: и расчета косинусного подобия между и . · Сигнатура метода (Method Signature, MS). Этот метод рассчитывает подобие сигнатур методов для всех возможных комбинаций следующим образом [28]: 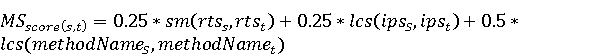 , где , где 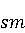 рассчитывает подобие на уровне токенов [8] между двумя типами возвращаемых значений, а рассчитывает подобие на уровне токенов [8] между двумя типами возвращаемых значений, а 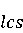 подсчитывает самую длинную общую последовательность между двумя заданными именами методов [29]. 3.2 Результаты. Расчет точности отображений, получаемых MIG и лучшими ранее известными подходами (LTR, TMAP [19] и MS [20]) представлен в [Таблица 1]. MIG имеет наилучшую точность среди всех подходов по всем правилам, изменяющуюся от 80% до 98%, что значительно выше других методов на 39.52% (как разница между средней точностью MIG для миграций 8 библиотек 86.98% и лучшей средней у других методов – 47.46%). подсчитывает самую длинную общую последовательность между двумя заданными именами методов [29]. 3.2 Результаты. Расчет точности отображений, получаемых MIG и лучшими ранее известными подходами (LTR, TMAP [19] и MS [20]) представлен в [Таблица 1]. MIG имеет наилучшую точность среди всех подходов по всем правилам, изменяющуюся от 80% до 98%, что значительно выше других методов на 39.52% (как разница между средней точностью MIG для миграций 8 библиотек 86.98% и лучшей средней у других методов – 47.46%).
Таблица 1
|
Правило миграции
|
LTR
|
TMAP
|
MS
|
MIG
|
|
logging->slf4j
|
28.26%
|
21.73%
|
26.08%
|
85.00%
|
|
comm-lang->slf4j
|
33.33%
|
33.33%
|
33.33%
|
89.90%
|
|
easymock->mockito
|
26.66%
|
46.66%
|
46.66%
|
80.00%
|
|
testing->junit
|
51.72%
|
51.72%
|
37.93%
|
98.00%
|
|
slf4j->log4j
|
77.77%
|
66.66%
|
77.77%
|
85.00%
|
|
json->gson
|
35.29%
|
47.05%
|
41.17%
|
85.00%
|
|
json-simple->gson
|
60.00%
|
60.00%
|
40.00%
|
92.90%
|
|
gson->jackson
|
66.66%
|
50.00%
|
50.00%
|
80.00%
|
|
Average Accuracy
|
47.46%
|
47.14%
|
44.12%
|
86.98%
|
Для объяснения разницы в точности результатов рассматриваемых подходов на [Рисунок 6] представлен результат миграции из json в gson. На [Рисунок 6] (A) все 4 метода смогли корректно рекомендовать замену метода 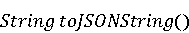 на на 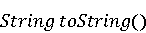 . MS смог найти правильную замену поскольку типы возвращаемых значений обоих методов одинаковы. Кроме того, наименования методов очень похожи. TMAP смог рекомендовать корректный целевой метод поскольку они имеют похожее описание и наименование . LTR дал правильный результат в силу схожести описаний , сигнатуры входных параметров и типа возвращаемого значения . Данные три признака имеют относительно высокие веса в сравнении с другими признаками, что значительно увеличивает точность алгоритма ранжирования. Напротив на [Рисунок 6] (B) только MIG смог рекомендовать правильный целевой метод «void addProperty(String property, Number value)». LTR рекомендует «voidaddProperty(Stringproperty, Stringvalue)» поскольку входной параметр «Stringvalue» имеет большую схожесть с исходным методом по и , чем схожесть «Number value» с правильным целевым методом, принимая во внимание что остальные признаки имеют одинаковые значения для обоих целевых методов. Ошибка произошла из-за полиморфной природы метода: LTR смог рекомендовать правильное наименование метода, но не тот, что имеет корректные параметры. TMAP рекомендовал «JsonElement parse(JsonReader json)» поскольку и имели большее подобие с исходным методом, чем корректный целевой метод. MS рекомендовал «JsonElement get(String memberName)» поскольку он имеет более высокое подобие сигнатур с исходным методом «put», чем корректный целевой метод с исходным методом. В обоих случаях [Рисунок 6] (A) и (B) MIG рекомендовал правильное отображение метода поскольку он «обучился» этим типам шаблонов через многочисленные деревья принятия решений. . MS смог найти правильную замену поскольку типы возвращаемых значений обоих методов одинаковы. Кроме того, наименования методов очень похожи. TMAP смог рекомендовать корректный целевой метод поскольку они имеют похожее описание и наименование . LTR дал правильный результат в силу схожести описаний , сигнатуры входных параметров и типа возвращаемого значения . Данные три признака имеют относительно высокие веса в сравнении с другими признаками, что значительно увеличивает точность алгоритма ранжирования. Напротив на [Рисунок 6] (B) только MIG смог рекомендовать правильный целевой метод «void addProperty(String property, Number value)». LTR рекомендует «voidaddProperty(Stringproperty, Stringvalue)» поскольку входной параметр «Stringvalue» имеет большую схожесть с исходным методом по и , чем схожесть «Number value» с правильным целевым методом, принимая во внимание что остальные признаки имеют одинаковые значения для обоих целевых методов. Ошибка произошла из-за полиморфной природы метода: LTR смог рекомендовать правильное наименование метода, но не тот, что имеет корректные параметры. TMAP рекомендовал «JsonElement parse(JsonReader json)» поскольку и имели большее подобие с исходным методом, чем корректный целевой метод. MS рекомендовал «JsonElement get(String memberName)» поскольку он имеет более высокое подобие сигнатур с исходным методом «put», чем корректный целевой метод с исходным методом. В обоих случаях [Рисунок 6] (A) и (B) MIG рекомендовал правильное отображение метода поскольку он «обучился» этим типам шаблонов через многочисленные деревья принятия решений.
Рисунок 6
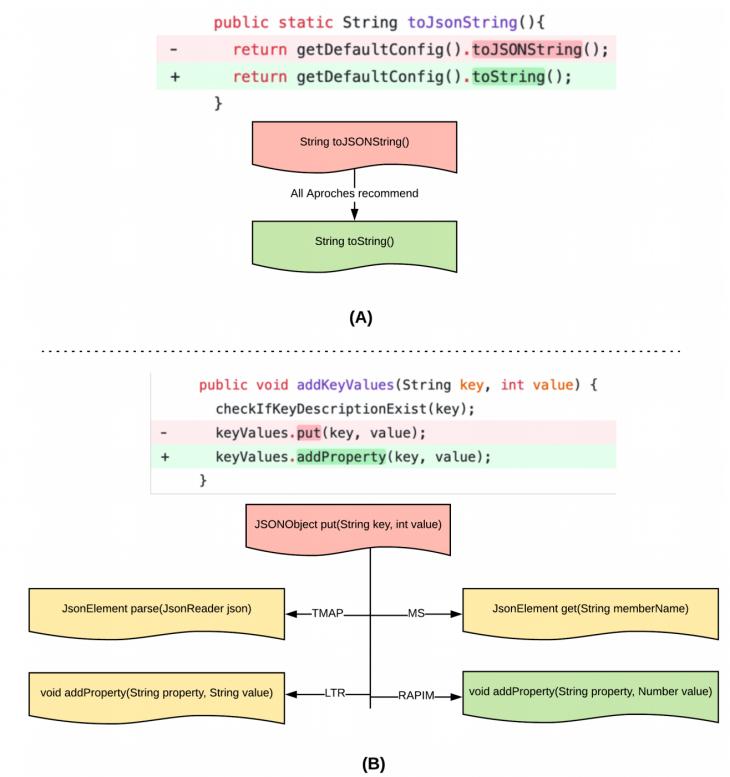
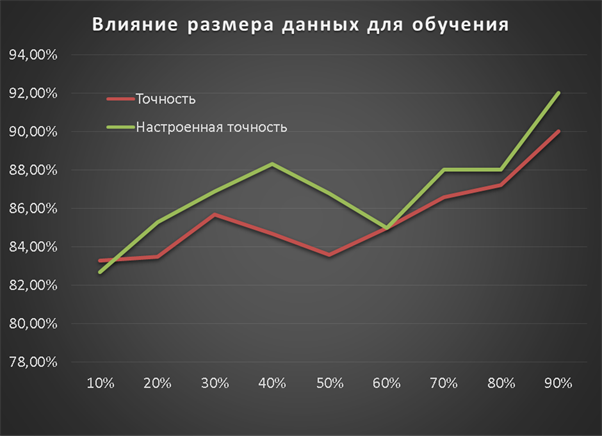
Анализ результатов показал, что для всех подходов довольно сложны следующие контексты: · Перезагрузка метода. Относится к двум методам, имеющим одинаковые названия, но различающиеся по количеству параметров, типу параметров или последовательности параметров. · Полиморфные методы. Они переопределены в иерархии классов, где метод дочернего класса имеет одинаковое наименование и количество параметров с методом базового класса, но с различными типами. · Обобщённые методы (Generics). Методы с входными и выходными параметрами, позволяющими методу работать с объектами различных типов. Также очень сложными являются случаи когда исходный и целевой методы различаются по названию, типу возвращаемого значения и даже входным параметрам. И наконец, существуют методы без должной документации, представляющие трудности для TMAP, LTR и MIG. На [Рисунок 7] показана зависимость точности рекомендаций MIG от количества данных, используемых для обучения. При увеличении количества данных для обучения точность увеличивается с 83.3% при 10% данных для обучения до 92% при 90% данных используемых для обучения. Это подтверждает независимость признаков и достаточность даже небольшого объема данных для достижения хорошей точности MIG.
Рисунок 7
4 Заключение В данном исследовании рассматривается проблема рекомендации сопоставления методов при миграции между сторонними библиотеками. Описан новый подход, рекомендующий сопоставление методов между двумя неизвестными библиотеками с использованием признаков, извлеченных из лексического сходства между именами методов и текстовым подобием документаций методов. Я оценил результат, проверяя, как данный подход и три других наиболее часто используемых подходов [19],[28] и [33] рекомендуют сопоставление методов миграции для 8 популярных библиотек. Я показал, что предлагаемый подход показывает гораздо лучшую точность и производительность, чем другие 3 метода. Качественный и количественный анализ результатов показывает увеличение точности на 39.51% в сравнении с другими широко известными подходами. В рамках будущих исследований я планирую значительно расширить количество используемых миграций наряду с более широким набором бинарных классификаторов. Я также планирую расширить количество признаков, включив также контекст использования методов в программном коде.
Библиография
[1. Hussein Alrubaye and Mohamed Wiem. Variability in library evolution. Software Engineering for Variability Intensive Systems: Foundations and Applications, page 295, 2019.
]
[2. Raula Gaikovina Kula, Daniel M German, Ali Ouni, Takashi Ishio, and Katsuro Inoue. Do developers update their library? Empirical Software Engineering, 23(1):384–417, 2018.
]
[3. Bradley E Cossette and Robert J Walker. Seeking the ground truth: a retroactive study on the evolution and migration of software libraries. In Proceedings of the ACM SIGSOFT 20th International Symposium on the Foundations of Software Engineering, page 55. ACM, 2012.
]
[4. Cedric Teyton, Jean-Remy Falleri, and Xavier Blanc. Mining library migration graphs. In Reverse Engineering (WCRE), 2012. 19th Working Conference on, pages 289–298. IEEE, 2012.
]
[5. Cedric Teyton, Jean-R´emy Falleri, and Xavier Blanc. Automatic discovery of function mappings between similar libraries. In Reverse Engineering (WCRE), 2013 20th Working Conference on, pages 192–201. IEEE, 2013.
]
[6. Hussein Alrubaye and Mohamed Wiem Mkaouer. Automating the detection of third-party java library migration at the function level. In Proceedings of the 28th Annual International Conference on Computer Science and Software Engineering, pages 60–71. IBM Corp., 2018.
]
[7. Hussein Alrubaye, Mohamed Wiem Mkaouer, and Ali Ouni. On the use of information retrieval to automate the detection of third-party java library migration at the function level. In 27th IEEE/ACM International Conference on Program Comprehension. IEEE, 2019.
]
[8. Miryung Kim, David Notkin, and Dan Grossman. Automatic inference of structural changes for matching across program versions. In ICSE, volume 7, pages 333–343. Citeseer, 2007.
]
[9. Thorsten Schafer, Jan Jonas, and Mira Mezini. Mining framework usage changes from instantiation code. In Proceedings of the 30th international conference on Software engineering, pages 471–480. ACM, 2008.
]
[10. Barthel´emy Dagenais and Martin P Robillard. Recommending adaptive changes for framework evolution. ACM Transactions on Software Engineering and Methodology (TOSEM), 20(4):19, 2011.
]
[11. Wei Wu, Yann-Gael Gu ¨ eh´ eneuc, Giuliano Antoniol, and Miryung Kim. Aura: a hybrid approach to identify framework evolution. In 2010 ACM/IEEE 32nd International Conference on Software Engineering, volume 1, pages 325–334. IEEE, 2010.
]
[12. Hao Zhong, Tao Xie, Lu Zhang, Jian Pei, and Hong Mei. Mapo: Mining and recommending api usage patterns. In European Conference on Object-Oriented Programming, pages 318–343. Springer, 2009.
]
[13. Collin McMillan, Mark Grechanik, Denys Poshyvanyk, Qing Xie and Chen Fu. Portfolio: finding relevant functions and their usage. In Proceedings of the 33rd International Conference on Software Engineering, pages 111–120. ACM, 2011.
]
[14. Ali Ouni, Raula Gaikovina Kula, Marouane Kessentini, Takashi Ishio, Daniel M German, and Katsuro Inoue. Search-based software library recommendation using multi-objective optimization. Information and Software Technology, 83:55–75, 2017.
]
[15. Johannes Hartel, Hakan Aksu, and Ralf L ¨ ammel. Classification of apis by hierarchical clustering. In Proceedings of the 26th Conference on Program Comprehension, pages 233–243. ACM, 2018.
]
[16. Daiki Katsuragawa, Akinori Ihara, Raula Gaikovina Kula, and Kenichi Matsumoto. Maintaining third-party libraries through domain-specific category recommendations. In 2018 IEEE/ACM 1st International Workshop on Software Health (SoHeal), pages 2–9. IEEE, 2018.
]
[17. Amruta Gokhale, Vinod Ganapathy, and Yogesh Padmanaban. Inferring likely mappings between apis. In Proceedings of the 2013 International Conference on Software Engineering, pages 82–91. IEEE Press, 2013.
]
[18. Rahul Pandita, Raoul Praful Jetley, Sithu D Sudarsan, and Laurie Williams. Discovering likely mappings between apis using text mining. In Source Code Analysis and Manipulation (SCAM), 2015 IEEE 15th International Working Conference on, pages 231–240. IEEE, 2015.
]
[19. Rahul Pandita, Raoul Jetley, Sithu Sudarsan, Timothy Menzies and Laurie Williams. Tmap: Discovering relevant api methods through text mining of api documentation. Journal of Software: Evolution and Process, 29(12), 2017.
]
[20. Ferdian Thung, David Lo, and Julia Lawall. Automated library recommendation. In 2013 20th Working Conference on Reverse Engineering (WCRE), pages 182–191. IEEE, 2013.
]
[21. Ferdian Thung, Richard J Oentaryo, David Lo, and Yuan Tian. Webapirec: Recommending web apis to software projects via personalized ranking. IEEE Transactions on Emerging Topics in Computational Intelligence, 1(3):145–156, 2017.
]
[22. Collin Mcmillan, Denys Poshyvanyk, Mark Grechanik, Qing Xie, and Chen Fu. Portfolio: Searching for relevant functions and their usages in millions of lines of code. ACM Transactions on Software Engineering and Methodology (TOSEM), 22(4):37, 2013.
]
[23. Collin McMillan, Mark Grechanik, and Denys Poshyvanyk. Detecting similar software applications. In Proceedings of the 34th International Conference on Software Engineering, pages 364–374. IEEE Press, 2012.
]
[24. Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and TAMT Meyarivan. A fast and elitist multiobjective genetic algorithm: Nsga-ii. IEEE transactions on evolutionary computation, 6(2):182–197, 2002.
]
[25. Amit Singhal et al. Modern information retrieval: A brief overview. IEEE Data Eng. Bull., 24(4):35–43, 2001.
]
[26. Lei Yu and Huan Liu. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the 20th international conference on machine learning (ICML-03), pages 856–863, 2003
]
[27. Tom Mitchell, Bruce Buchanan, Gerald DeJong, Thomas Dietterich, Paul Rosenbloom, and Alex Waibel. Machine learning. Annual review of computer science, 4(1):417–433, 1990.
]
[28. Hoan Anh Nguyen, Tung Thanh Nguyen, Gary Wilson Jr, Anh Tuan Nguyen, Miryung Kim, and Tien N Nguyen. A graphbased approach to api usage adaptation. In ACM Sigplan Notices, volume 45, pages 302–321. ACM, 2010.
]
[29. James W Hunt and Thomas G Szymanski. A fast algorithm for computing longest common subsequences. Communications of the ACM, 20(5):350–353, 1977.
]
[30. Andrea Arcuri and Gordon Fraser. Parameter tuning or default values? an empirical investigation in search-based software engineering. Empirical Software Engineering, 18(3):594–623, 2013.
]
[31. Alessandro Del Sole. Introducing microsoft cognitive services. In Microsoft Computer Vision APIs Distilled, pages 1–4. Springer, 2018.
]
[32. Edward Loper and Steven Bird. Nltk: the natural language toolkit. arXiv preprint cs/0205028, 2002.
]
[33. Xin Ye, Razvan Bunescu, and Chang Liu. Learning to rank relevant files for bug reports using domain knowledge. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, pages 689–699. ACM, 2014.
]
References
[1. Hussein Alrubaye and Mohamed Wiem. Variability in library evolution. Software Engineering for Variability Intensive Systems: Foundations and Applications, page 295, 2019.
]
[2. Raula Gaikovina Kula, Daniel M German, Ali Ouni, Takashi Ishio, and Katsuro Inoue. Do developers update their library? Empirical Software Engineering, 23(1):384–417, 2018.
]
[3. Bradley E Cossette and Robert J Walker. Seeking the ground truth: a retroactive study on the evolution and migration of software libraries. In Proceedings of the ACM SIGSOFT 20th International Symposium on the Foundations of Software Engineering, page 55. ACM, 2012.
]
[4. Cedric Teyton, Jean-Remy Falleri, and Xavier Blanc. Mining library migration graphs. In Reverse Engineering (WCRE), 2012. 19th Working Conference on, pages 289–298. IEEE, 2012.
]
[5. Cedric Teyton, Jean-R´emy Falleri, and Xavier Blanc. Automatic discovery of function mappings between similar libraries. In Reverse Engineering (WCRE), 2013 20th Working Conference on, pages 192–201. IEEE, 2013.
]
[6. Hussein Alrubaye and Mohamed Wiem Mkaouer. Automating the detection of third-party java library migration at the function level. In Proceedings of the 28th Annual International Conference on Computer Science and Software Engineering, pages 60–71. IBM Corp., 2018.
]
[7. Hussein Alrubaye, Mohamed Wiem Mkaouer, and Ali Ouni. On the use of information retrieval to automate the detection of third-party java library migration at the function level. In 27th IEEE/ACM International Conference on Program Comprehension. IEEE, 2019.
]
[8. Miryung Kim, David Notkin, and Dan Grossman. Automatic inference of structural changes for matching across program versions. In ICSE, volume 7, pages 333–343. Citeseer, 2007.
]
[9. Thorsten Schafer, Jan Jonas, and Mira Mezini. Mining framework usage changes from instantiation code. In Proceedings of the 30th international conference on Software engineering, pages 471–480. ACM, 2008.
]
[10. Barthel´emy Dagenais and Martin P Robillard. Recommending adaptive changes for framework evolution. ACM Transactions on Software Engineering and Methodology (TOSEM), 20(4):19, 2011.
]
[11. Wei Wu, Yann-Gael Gu ¨ eh´ eneuc, Giuliano Antoniol, and Miryung Kim. Aura: a hybrid approach to identify framework evolution. In 2010 ACM/IEEE 32nd International Conference on Software Engineering, volume 1, pages 325–334. IEEE, 2010.
]
[12. Hao Zhong, Tao Xie, Lu Zhang, Jian Pei, and Hong Mei. Mapo: Mining and recommending api usage patterns. In European Conference on Object-Oriented Programming, pages 318–343. Springer, 2009.
]
[13. Collin McMillan, Mark Grechanik, Denys Poshyvanyk, Qing Xie and Chen Fu. Portfolio: finding relevant functions and their usage. In Proceedings of the 33rd International Conference on Software Engineering, pages 111–120. ACM, 2011.
]
[14. Ali Ouni, Raula Gaikovina Kula, Marouane Kessentini, Takashi Ishio, Daniel M German, and Katsuro Inoue. Search-based software library recommendation using multi-objective optimization. Information and Software Technology, 83:55–75, 2017.
]
[15. Johannes Hartel, Hakan Aksu, and Ralf L ¨ ammel. Classification of apis by hierarchical clustering. In Proceedings of the 26th Conference on Program Comprehension, pages 233–243. ACM, 2018.
]
[16. Daiki Katsuragawa, Akinori Ihara, Raula Gaikovina Kula, and Kenichi Matsumoto. Maintaining third-party libraries through domain-specific category recommendations. In 2018 IEEE/ACM 1st International Workshop on Software Health (SoHeal), pages 2–9. IEEE, 2018.
]
[17. Amruta Gokhale, Vinod Ganapathy, and Yogesh Padmanaban. Inferring likely mappings between apis. In Proceedings of the 2013 International Conference on Software Engineering, pages 82–91. IEEE Press, 2013.
]
[18. Rahul Pandita, Raoul Praful Jetley, Sithu D Sudarsan, and Laurie Williams. Discovering likely mappings between apis using text mining. In Source Code Analysis and Manipulation (SCAM), 2015 IEEE 15th International Working Conference on, pages 231–240. IEEE, 2015.
]
[19. Rahul Pandita, Raoul Jetley, Sithu Sudarsan, Timothy Menzies and Laurie Williams. Tmap: Discovering relevant api methods through text mining of api documentation. Journal of Software: Evolution and Process, 29(12), 2017.
]
[20. Ferdian Thung, David Lo, and Julia Lawall. Automated library recommendation. In 2013 20th Working Conference on Reverse Engineering (WCRE), pages 182–191. IEEE, 2013.
]
[21. Ferdian Thung, Richard J Oentaryo, David Lo, and Yuan Tian. Webapirec: Recommending web apis to software projects via personalized ranking. IEEE Transactions on Emerging Topics in Computational Intelligence, 1(3):145–156, 2017.
]
[22. Collin Mcmillan, Denys Poshyvanyk, Mark Grechanik, Qing Xie, and Chen Fu. Portfolio: Searching for relevant functions and their usages in millions of lines of code. ACM Transactions on Software Engineering and Methodology (TOSEM), 22(4):37, 2013.
]
[23. Collin McMillan, Mark Grechanik, and Denys Poshyvanyk. Detecting similar software applications. In Proceedings of the 34th International Conference on Software Engineering, pages 364–374. IEEE Press, 2012.
]
[24. Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and TAMT Meyarivan. A fast and elitist multiobjective genetic algorithm: Nsga-ii. IEEE transactions on evolutionary computation, 6(2):182–197, 2002.
]
[25. Amit Singhal et al. Modern information retrieval: A brief overview. IEEE Data Eng. Bull., 24(4):35–43, 2001.
]
[26. Lei Yu and Huan Liu. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the 20th international conference on machine learning (ICML-03), pages 856–863, 2003
]
[27. Tom Mitchell, Bruce Buchanan, Gerald DeJong, Thomas Dietterich, Paul Rosenbloom, and Alex Waibel. Machine learning. Annual review of computer science, 4(1):417–433, 1990.
]
[28. Hoan Anh Nguyen, Tung Thanh Nguyen, Gary Wilson Jr, Anh Tuan Nguyen, Miryung Kim, and Tien N Nguyen. A graphbased approach to api usage adaptation. In ACM Sigplan Notices, volume 45, pages 302–321. ACM, 2010.
]
[29. James W Hunt and Thomas G Szymanski. A fast algorithm for computing longest common subsequences. Communications of the ACM, 20(5):350–353, 1977.
]
[30. Andrea Arcuri and Gordon Fraser. Parameter tuning or default values? an empirical investigation in search-based software engineering. Empirical Software Engineering, 18(3):594–623, 2013.
]
[31. Alessandro Del Sole. Introducing microsoft cognitive services. In Microsoft Computer Vision APIs Distilled, pages 1–4. Springer, 2018.
]
[32. Edward Loper and Steven Bird. Nltk: the natural language toolkit. arXiv preprint cs/0205028, 2002.
]
[33. Xin Ye, Razvan Bunescu, and Chang Liu. Learning to rank relevant files for bug reports using domain knowledge. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, pages 689–699. ACM, 2014.
]
Результаты процедуры рецензирования статьи
Рецензия скрыта по просьбе автора
|
 Рус
Рус










